使用ONNX Runtime加速LLaMA-2推理
作者:Kunal Vaishnavi 和 Parinita Rahi
2023年11月14日 (2023年11月22日更新)
想更快地執行Llama2嗎?讓我們探索ONNX Runtime如何推動您的Llama2變體,實現更快的推理!
得益於ONNX Runtime的尖端融合和核心最佳化,現在您可以體驗到顯著的推理效能提升——對於7B、13B和70B模型,速度提升高達3.8倍。本部落格詳細介紹了效能增強、深入探討了ONNX Runtime的融合最佳化、多GPU推理支援,並指導您如何利用ONNX Runtime的跨平臺能力,在不同平臺上實現無縫推理。這是一系列即將釋出的部落格中的第一篇,後續部落格將涵蓋ONNX Runtime量化更新帶來的高效記憶體使用以及跨平臺使用場景的更多方面。
背景:Llama2與微軟
Llama2是Meta公司推出的最先進的開源LLM,規模從7B到70B引數不等(7B、13B、70B)。微軟和Meta於2023年7月宣佈了他們在Azure和Windows上的人工智慧合作。作為該公告的一部分,Llama2被新增到Azure AI模型目錄中,該目錄是基礎模型的中心,使開發人員和機器學習(ML)專業人員能夠輕鬆發現、評估、自定義和大規模部署預構建的大型AI模型。
ONNX Runtime允許使用者輕鬆地將這種生成式AI模型的能力整合到您的應用程式和服務中,並透過最佳化的改進,實現更快的推理速度並降低成本。
利用新的ONNX Runtime最佳化實現更快的推理
作為新發布的1.16.2版本的一部分,ONNX Runtime現在為Llama2提供了多項內建最佳化,包括圖融合和核心最佳化。與PyTorch編譯模式下CUDA FP16的提示延遲相比,Llama2的Hugging Face (HF) 變體的推理加速情況如下所述。下面顯示端到端吞吐量或實際執行吞吐量的定義為:批大小 * (提示長度 + 令牌生成長度) / 實際執行延遲,其中實際執行延遲 = 端到端執行的延遲,令牌生成長度 = 256個生成的令牌。與PyTorch編譯模式相比,端到端吞吐量在13B模型上增加了2.4倍,在7B模型上增加了1.8倍。對於更高批大小和序列長度的組合,例如(16, 2048),PyTorch的 eager 模式會超時,而ORT則顯示出優於編譯模式的效能。
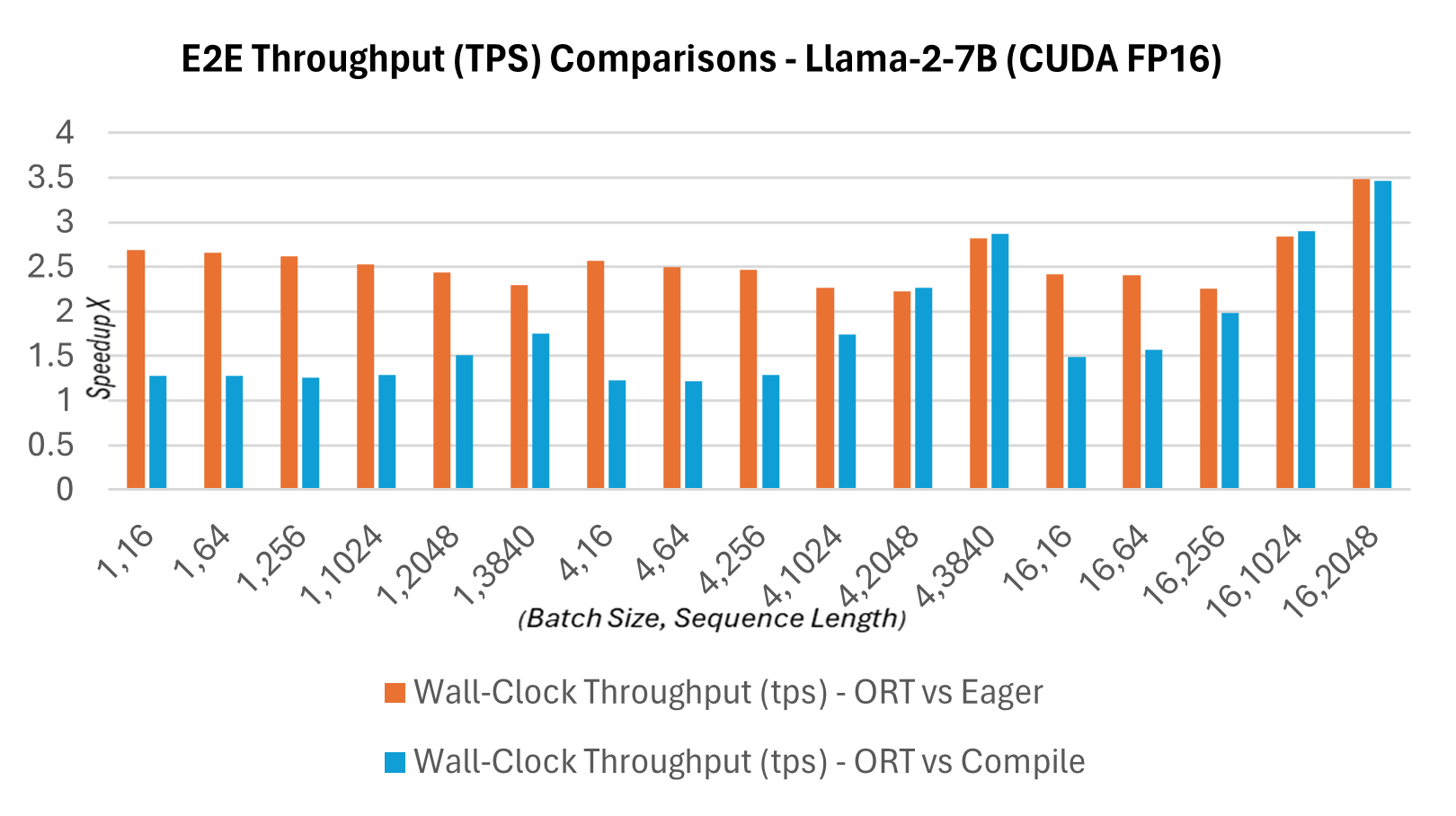

延遲與吞吐量
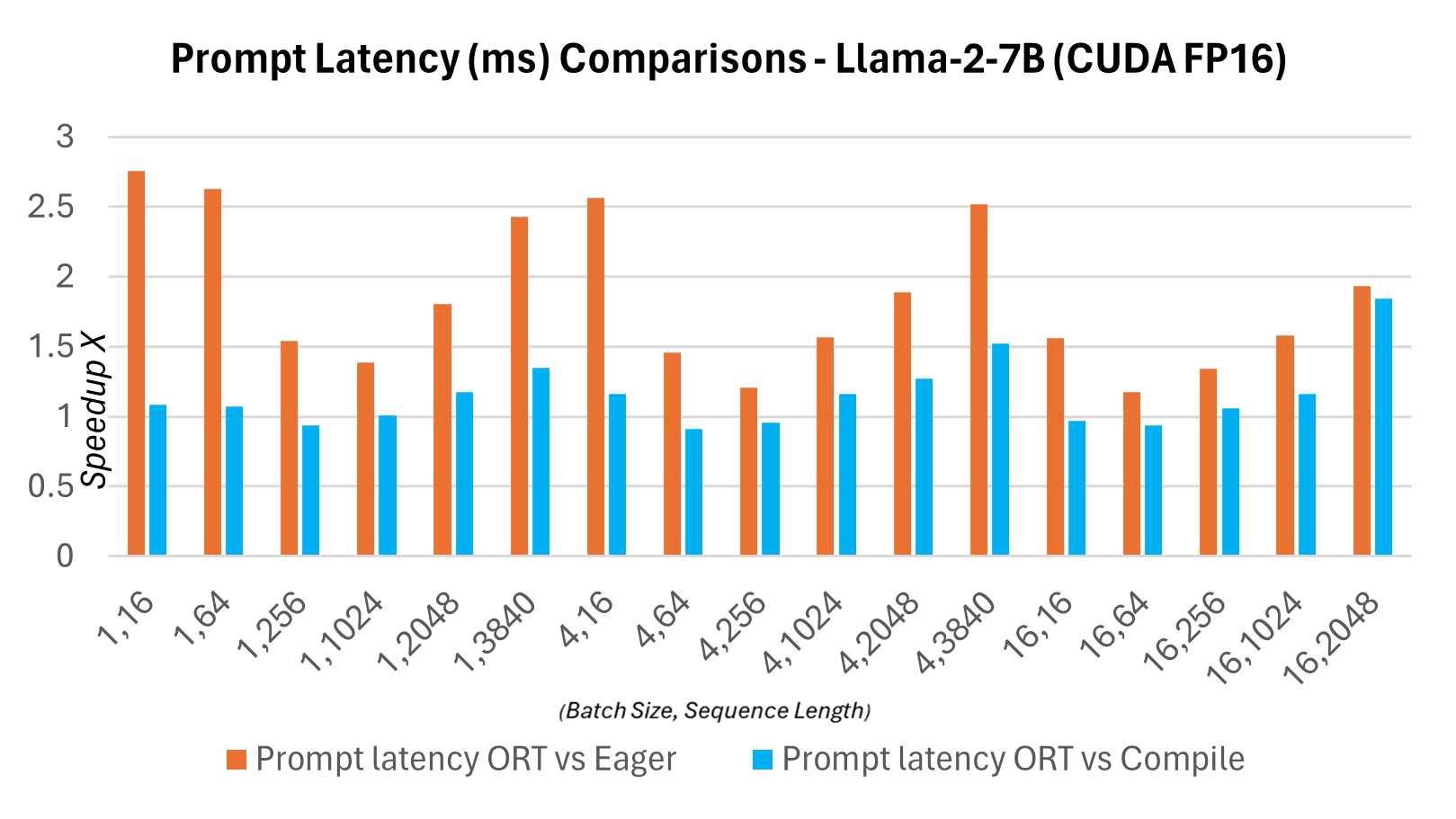
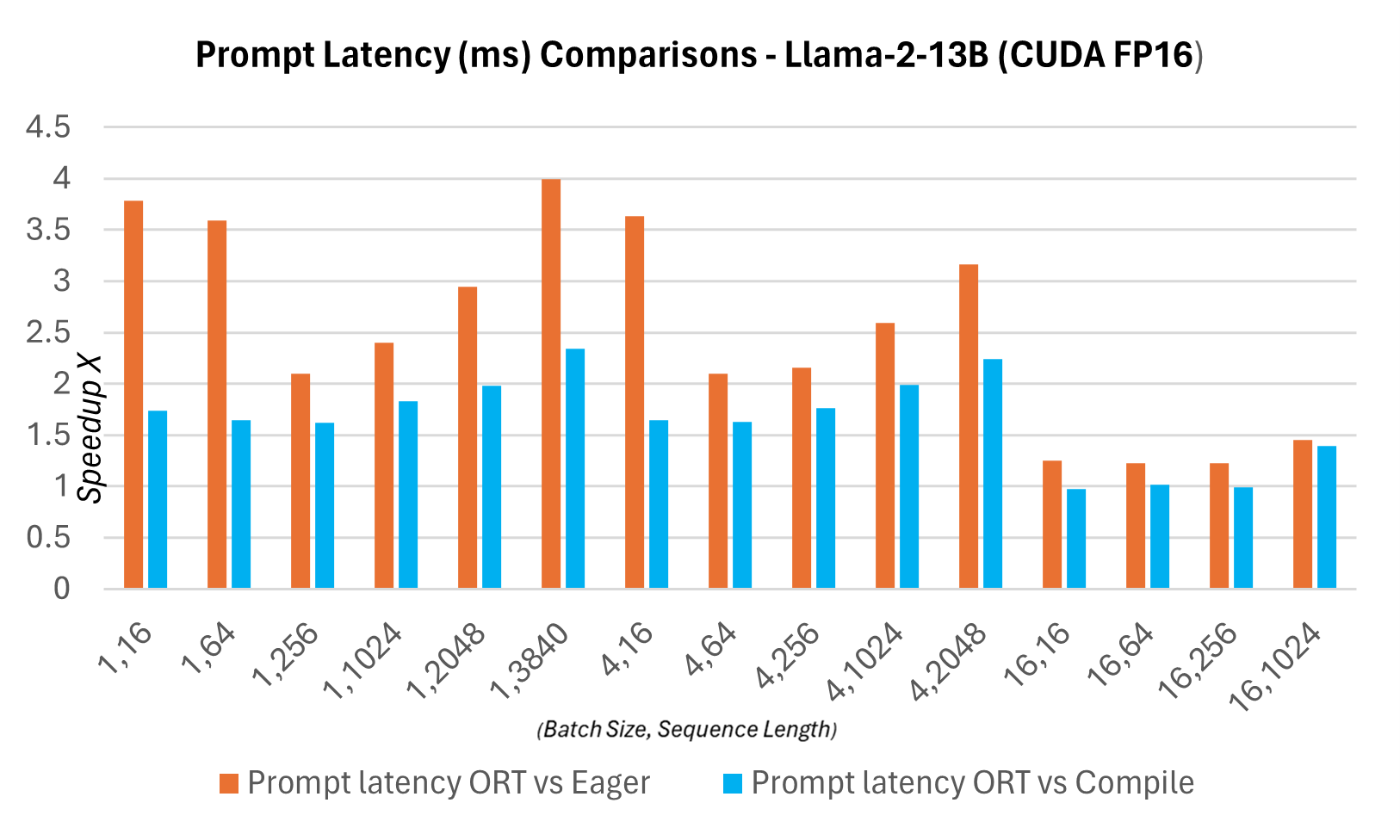
下圖顯示了ONNX Runtime與PyTorch版本的Llama2 7B模型在CUDA FP16上的延遲對比。這裡的延遲定義為模型完成一次前向傳播,生成logits並同步輸出所需的時間。
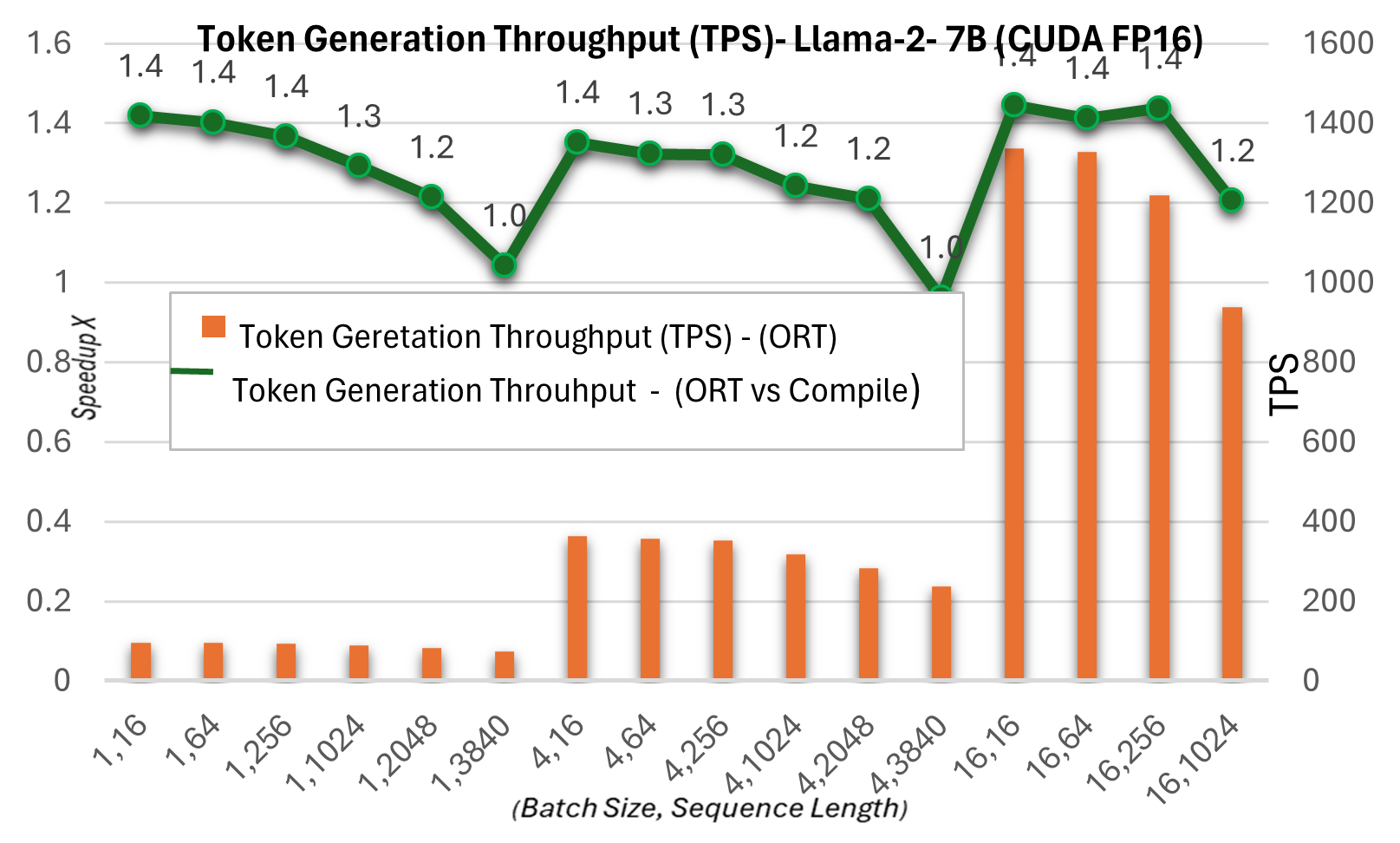
下面的令牌生成吞吐量是前256個生成令牌的平均吞吐量。與PyTorch編譯模式相比,令牌生成吞吐量在7B模型上最高提升約1.3倍,在13B模型上最高提升約1.5倍。
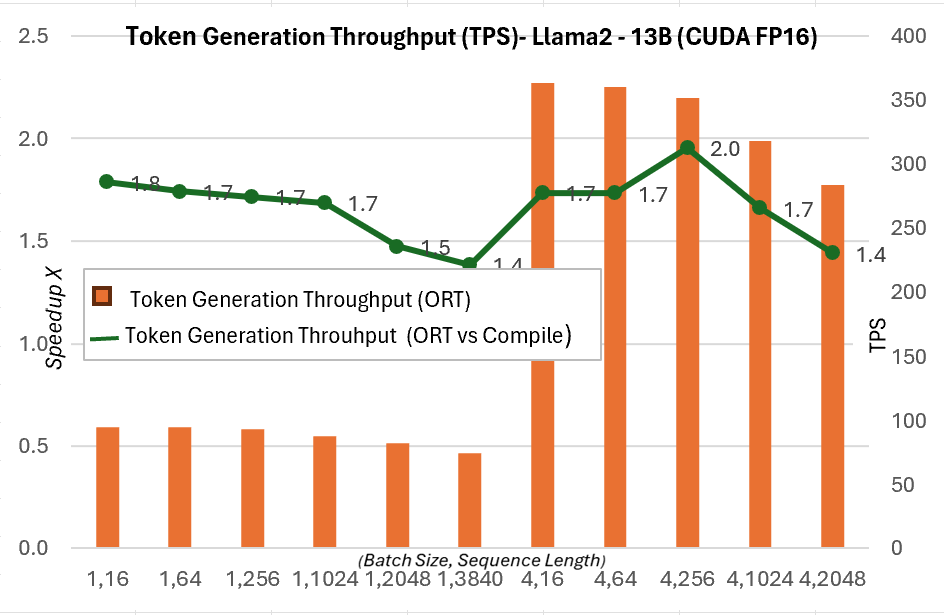
有關這些指標的更多詳細資訊,請參見此處。
ONNX Runtime與多GPU推理
ONNX Runtime支援多GPU推理,以支援大型模型的部署。即使在FP16精度下,LLaMA-2 70B模型也需要140GB記憶體。即使配備強大的NVIDIA A100 80GB GPU,載入模型也需要多個GPU進行推理。
ONNX Runtime在70B模型上應用了Megatron-LM張量並行,以將原始模型權重分割到不同的GPU上。對70B模型進行的Megatron分片將FP16精度的PyTorch模型分片為4個分割槽,將每個分割槽轉換為ONNX格式,然後對轉換後的ONNX模型應用新的ONNX Runtime圖融合。透過這些最佳化,70B模型在批大小為1時,令牌生成吞吐量約為每秒30個令牌,對於較短序列長度的端到端吞吐量也從30 tps開始。您可以在此處找到更多示例指令碼。
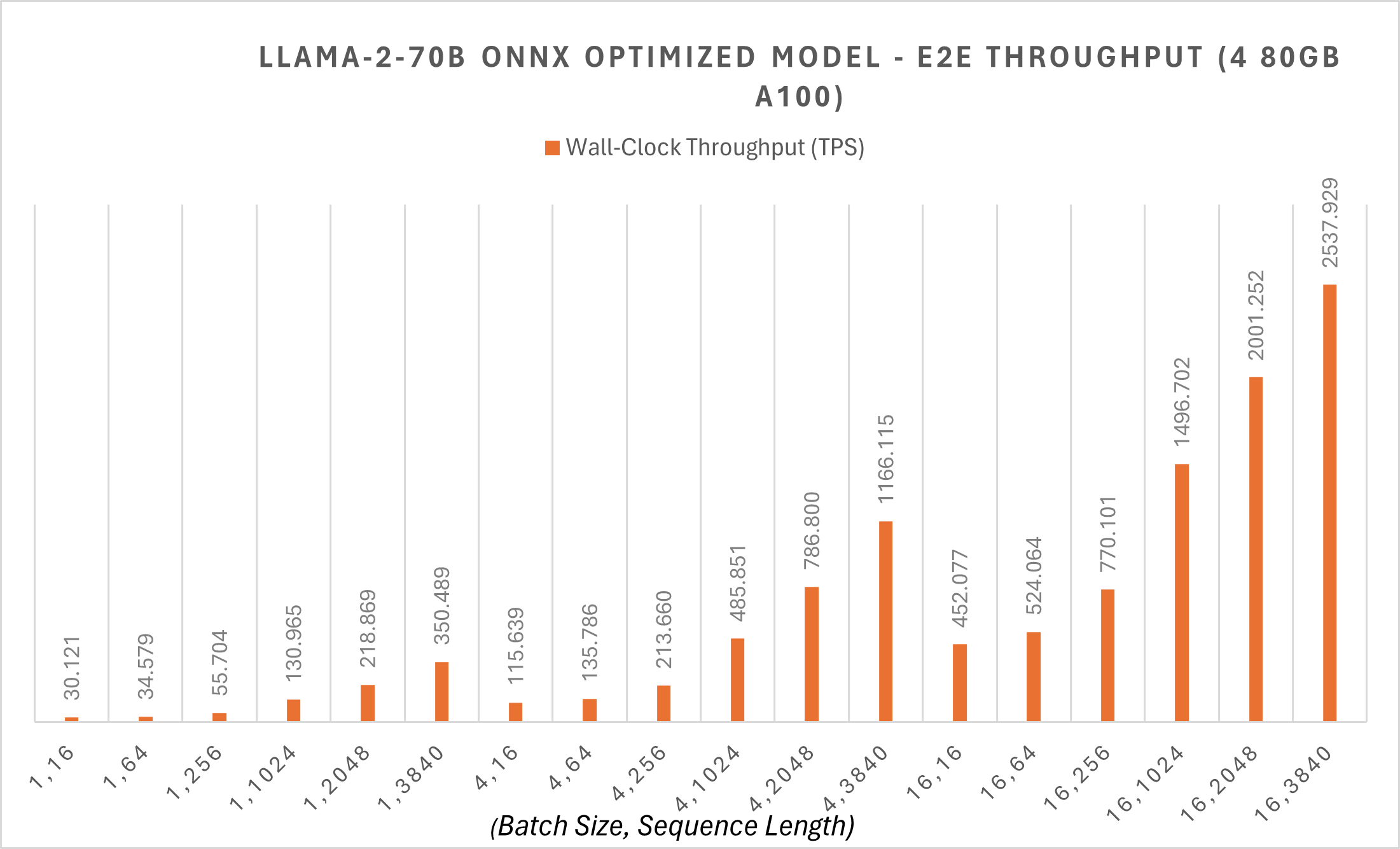
ONNX Runtime最佳化

ONNX Runtime用於最佳化的技術,如圖融合,適用於最先進的模型。隨著這些模型變得更加複雜,應用圖融合的技術也會相應調整以適應額外的複雜性。例如,ONNX Runtime現在支援自動化模式匹配,而不是手動匹配圖中的融合模式。與其手動檢測大型子圖並匹配它們形成的眾多路徑,不如將大型模組匯出為函式,然後針對函式的規範進行模式匹配,從而識別融合機會。

舉一個具體的例子,圖6是構成旋轉位置編碼計算的節點示例。針對此子圖進行模式匹配很麻煩,因為需要驗證的路徑數量很多。透過將其匯出為函式,圖的父檢視將只顯示輸入和輸出,並將所有這些節點表示為一個單一的運算子。
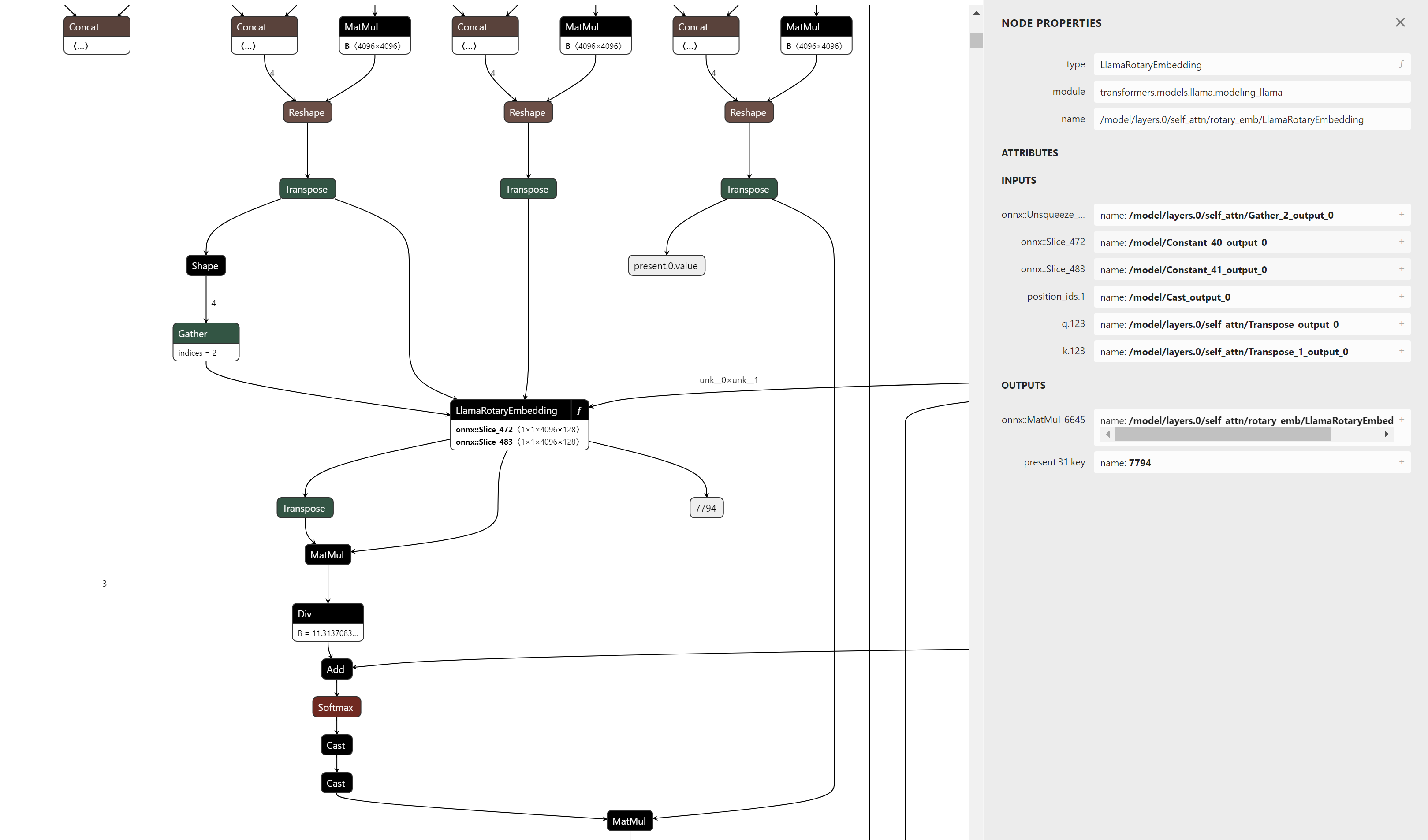
這種方法使得維護和支援未來版本的旋轉位置編碼計算變得更加容易,因為模式匹配僅取決於運算子的輸入和輸出,而不是其內部語義表示。它還允許在GPT-NeoX、Falcon、Mistral、Zephyr等類似模型中現有旋轉位置編碼的實現進行模式匹配和融合,幾乎無需更改。
ONNX Runtime還增加了對GroupQueryAttention (GQA) 運算子的支援,該運算子利用新的Flash Attention V2演算法及其最佳化核心來高效計算注意力。GQA運算子支援過去鍵/值快取(past KV cache)和當前鍵/值快取(present KV cache)之間的過去-當前緩衝區共享。透過將當前KV快取繫結到過去KV快取,無需為兩個快取單獨分配裝置記憶體。相反,過去KV快取可以預先分配足夠的裝置記憶體,以便在推理過程中無需請求新的裝置記憶體。這減少了在計算密集型工作負載期間KV快取變大時的記憶體使用,並透過消除裝置記憶體分配請求來降低延遲。過去-當前緩衝區共享可以啟用或停用,而無需更改ONNX模型,這為終端使用者提供了更大的靈活性,讓他們決定哪種方法最適合自己。
除了這些融合和核心最佳化之外,ONNX Runtime還減少了模型的記憶體使用。除了量化改進(將在未來的文章中介紹)之外,ONNX Runtime將每個旋轉位置編碼中使用的餘弦和正弦快取的大小壓縮了50%。ONNX Runtime中執行旋轉位置編碼計算的計算核心可以識別這種格式,並使用其並行實現更高效地計算旋轉位置編碼,同時減少記憶體使用。旋轉位置編碼計算核心還支援交錯和非交錯格式,以分別支援Microsoft版本的LLaMA-2和Hugging Face版本的LLaMA-2,同時共享相同的計算。
這些最佳化適用於Hugging Face版本(以-hf結尾的模型)和微軟版本。您可以從微軟的LLaMA-2 ONNX倉庫下載最佳化後的HF版本。敬請期待即將推出的新版微軟版本!
使用Olive最佳化您的模型
Olive是一款硬體感知模型最佳化工具,它集成了模型壓縮、最佳化和編譯等先進技術。我們已透過Olive提供ONNX Runtime最佳化,讓您能夠以簡單的體驗為特定硬體簡化整個最佳化過程。
這是一個使用Olive進行Llama2最佳化的示例,它利用了本部落格中強調的ONNX Runtime最佳化。不同的最佳化流程可滿足各種需求。例如,您可以根據自己的精度容忍度,靈活選擇CPU和GPU推理中量化的不同資料型別。此外,您還可以在客戶端GPU上使用Olive-QLoRa微調自己的Llama2模型,並利用ONNX Runtime最佳化進行推理。
使用示例
這是一個示例notebook,它向您展示瞭如何在您的應用程式中端到端地使用上述ONNX Runtime最佳化。
結論
本部落格中討論的進步使得Llama2能夠透過ONNX Runtime實現更快的推理,為AI應用和研究提供了激動人心的可能性。隨著效能和效率的提升,創新前景廣闊,我們熱切期待其充滿活力的開發者社群能夠利用Llama2和ONNX Runtime構建新的應用。敬請關注更多更新!