ONNX Runtime 支援跨平臺和裝置的 Phi-3 mini 模型
2024年4月22日
得益於 ONNX Runtime 和 DirectML,您現在可以在廣泛的裝置和平臺上執行 Microsoft 最新的自家Phi-3 模型。今天,我們很榮幸地宣佈在第一時間支援兩種版本的 Phi-3:phi3-mini-4k-instruct 和 phi3-mini-128k-instruct。最佳化後的 ONNX 模型可分別在phi3-mini-4k-instruct-onnx 和 phi3-mini-128k-instruct-onnx 獲取。
許多語言模型過大,無法在大多數裝置上本地執行,但 Phi-3 是一個顯著的例外:這個小而強大的模型套件達到了比其大10倍的模型相當的效能!Phi-3 Mini 也是同級別模型中第一個支援長達 128K 令牌長上下文的模型。要了解更多關於 Microsoft 如何透過戰略性資料整理和創新擴充套件實現這些卓越成果的資訊,請參閱此處。
您可以使用我們新推出的 ONNX Runtime Generate() API 輕鬆開始使用 Phi-3,該 API 位於此處!
DirectML 和 ONNX Runtime 在 Windows 上擴充套件 Phi-3 Mini
Phi-3 本身已經足夠小,可以在許多 Windows 裝置上執行,但為什麼止步於此呢?透過量化使 Phi-3 更小將大大擴大模型在 Windows 上的覆蓋範圍,但並非所有量化技術都是平等的。我們希望在確保可擴充套件性的同時,也保持模型精度。
使用啟用感知量化 (AWQ) 量化 Phi-3 Mini 讓我們能夠從量化中獲得記憶體節省,同時對精度影響最小。AWQ 透過識別保持模型精度所需的最高 1% 顯著權重,並量化其餘 99% 的權重來實現這一點。這導致使用 AWQ 進行量化時,精度損失比許多其他量化技術要小得多。有關 AWQ 的更多資訊,請參閱此處。
無論您的 GPU 是 AMD、Intel 還是 NVIDIA,只要支援 DirectX 12,都可以在 Windows 上執行 DirectML。DirectML 和 ONNX Runtime 現在支援 INT4 AWQ,這意味著開發人員現在可以在數億 Windows 裝置上執行和部署此量化版本的 Phi-3!
我們正在與硬體供應商合作伙伴合作,提供驅動程式更新,這將在未來幾周進一步提高效能。請在五月下旬參加我們的Build 演講以瞭解更多資訊!
具體效能資料請參見下文。
ONNX Runtime 移動版
除了支援 Windows 上的兩種 Phi-3 Mini 模型外,ONNX Runtime 還可以幫助在其他客戶端裝置(包括移動和 Mac CPU)上執行這些模型,使其成為真正的跨平臺框架。ONNX Runtime 還支援 RTN 等量化技術,使這些模型能夠在多種不同型別的硬體上執行。
ONNX Runtime Mobile 使開發人員能夠在移動和邊緣裝置上使用 AI 模型執行裝置端推理。透過消除客戶端-伺服器通訊,ORT Mobile 提供了隱私保護且零成本。使用 RTN INT4 量化,我們顯著減小了最先進的 Phi-3 Mini 模型的大小,並且可以在三星 Galaxy S21 上以中等速度執行。當應用 RTN INT4 量化時,有一個用於 int4 精度級別的調優引數。此引數指定了 int4 量化中 MatMul 啟用所需的最低精度級別,以平衡效能和精度之間的權衡。已釋出兩個版本的 RTN 量化模型:int4_accuracy_level=1(針對精度最佳化)和 int4_accuracy_level=4(針對性能最佳化)。如果您更喜歡更好的效能但略微犧牲精度,我們建議使用 int4_accuracy_level=4 的模型。
ONNX Runtime 用於伺服器場景
對於 Linux 開發者及其他使用者,帶有 CUDA 的 ONNX Runtime 是一個出色的解決方案,它支援廣泛的 NVIDIA GPU,包括消費級和資料中心 GPU。對於所有批處理大小、提示長度組合,ONNX Runtime 與 CUDA 執行 Phi-3 Mini-128K-Instruct 的效能優於 PyTorch。
對於 FP16 CUDA 和 INT4 CUDA,Phi-3 Mini-128K-Instruct 在 ORT 下的效能分別比 PyTorch 快 5 倍和 9 倍。Llama.cpp 目前不支援 Phi-3 Mini-128K-Instruct。
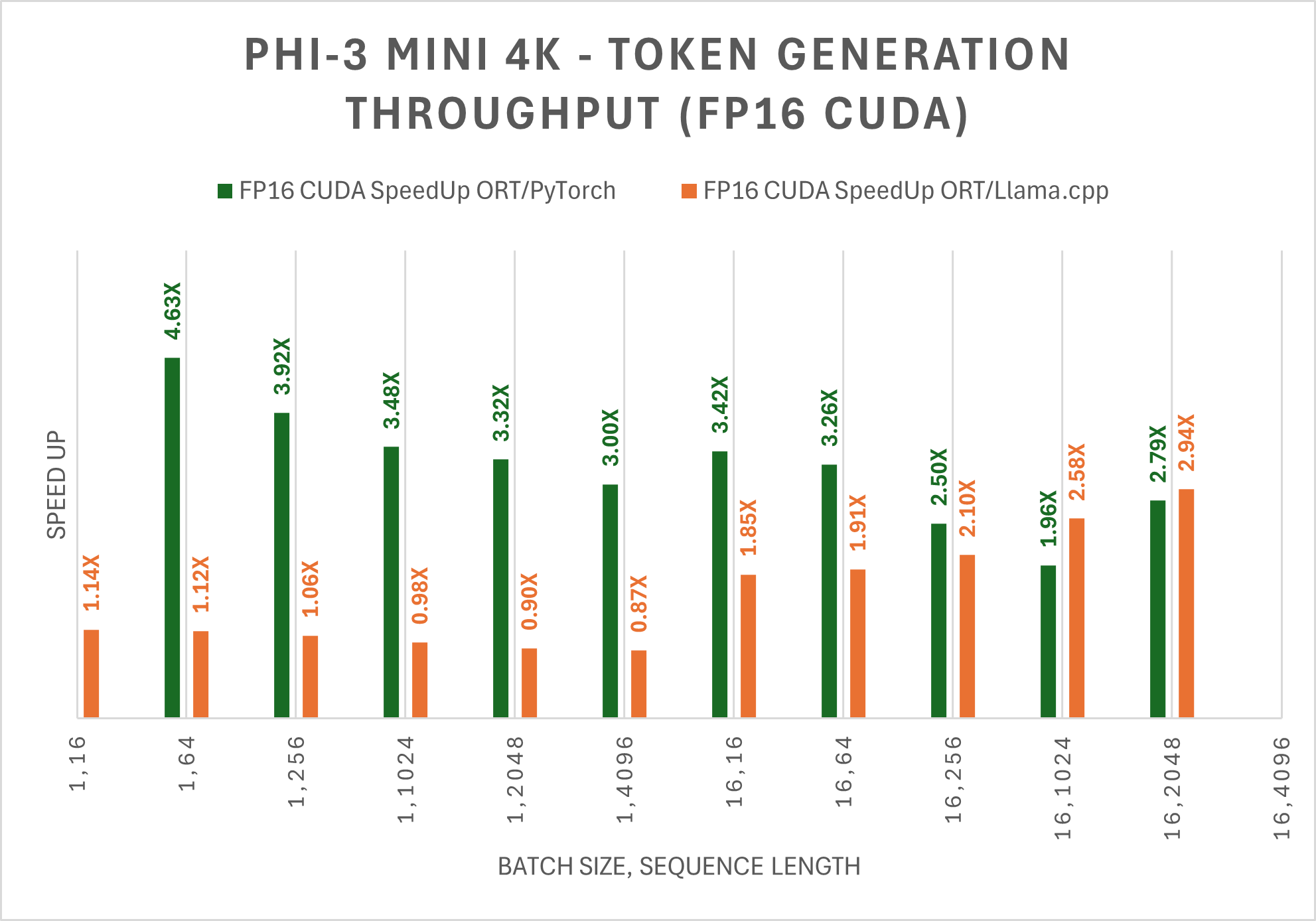
對於 FP16 和 INT4 CUDA,Phi-3 Mini-4K-Instruct 在 ORT 下的效能分別比 PyTorch 快 5 倍和 10 倍。對於長序列長度,Phi-3 Mini-4K-Instruct 也比 Llama.cpp 快 3 倍。
無論是 Windows、Linux、Android 還是 Mac,都有透過 ONNX Runtime 高效推理模型的途徑!
嘗試 ONNX Runtime Generate() API
我們很高興地宣佈推出新的 Generate() API,該 API 透過封裝生成式 AI 推理的多個方面,使在各種裝置、平臺和 EP 後端上執行 Phi-3 模型變得更加容易。Generate() API 使您能夠輕鬆地將 LLM 直接拖放到您的應用程式中。要使用 ONNX 執行這些模型的早期版本,請按照此處的步驟進行操作。
示例
python model-qa.py -m /YourModelPath/onnx/cpu_and_mobile/phi-3-mini-4k-instruct-int4-cpu -k 40 -p 0.95 -t 0.8 -r 1.0
Input: <user> Tell me a joke <end>
Output: <assistant> Why don't scientists trust atoms?
Because they make up everything!
This joke plays on the double meaning of "make up." In science, atoms are the fundamental building blocks of matter,
literally making up everything. However, in a colloquial sense, "to make up" can mean to fabricate or lie, hence the humor. <end>
請關注此處,獲取有關 AMD 的更多更新以及 ORT 1.18 的額外最佳化。此外,請在五月下旬檢視我們的Build 演講,瞭解更多有關此 API 的資訊!
效能指標
DirectML
DirectML 不僅能讓開發人員實現出色的效能,還能在 AMD、Intel 和 NVIDIA 的支援下,將模型部署到整個 Windows 生態系統。最棒的是,AWQ 意味著開發人員在獲得這種規模的同時,還能保持高模型精度。
敬請期待未來幾周的更多效能改進,這得益於我們的硬體合作伙伴最佳化的驅動程式以及 ONNX Generate() API 的額外更新。
| 提示長度 | 生成長度 | 實際每秒令牌數 |
|---|---|---|
| 16 | 256 | 266.65 |
| 16 | 512 | 251.63 |
| 16 | 1024 | 238.87 |
| 16 | 2048 | 217.5 |
| 32 | 256 | 278.53 |
| 32 | 512 | 259.73 |
| 32 | 1024 | 241.72 |
| 32 | 2048 | 219.3 |
| 64 | 256 | 308.26 |
| 64 | 512 | 272.47 |
| 64 | 1024 | 245.67 |
| 64 | 2048 | 220.55 |
CUDA
下表顯示了 Phi-3 Mini 128K Instruct ONNX 模型生成的前 256 個令牌的平均吞吐量(tps)的改進。這些比較是在 CUDA 上,針對 FP16 和 INT4 精度進行的測量,測量裝置為一塊 A100 80GB GPU(SKU:Standard_ND96amsr_A100_v4)。
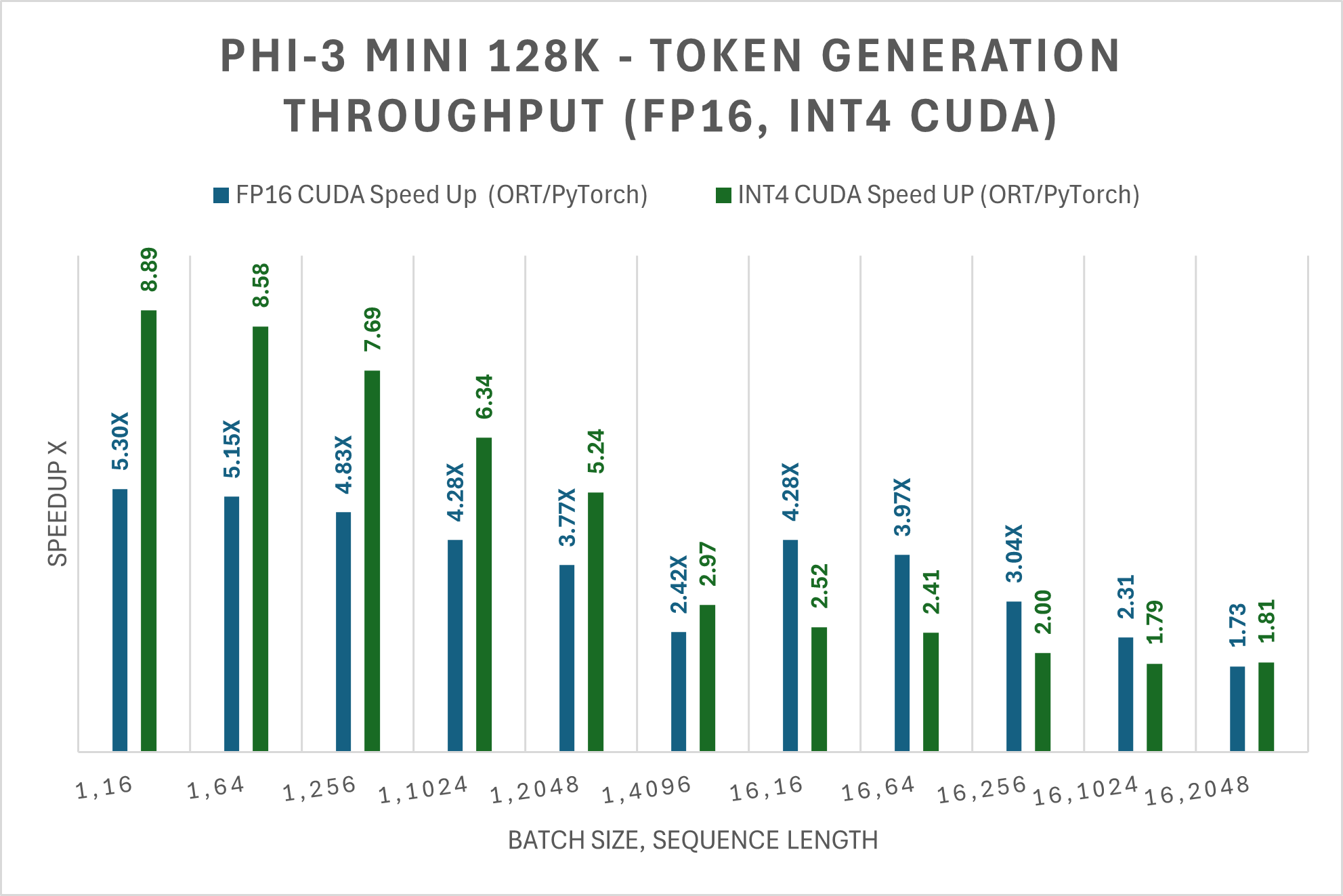 注意:PyTorch Compile 和 Llama.cpp 目前不支援 Phi-3 Mini 128K Instruct 模型。
注意:PyTorch Compile 和 Llama.cpp 目前不支援 Phi-3 Mini 128K Instruct 模型。下表顯示了 Phi-3 Mini 4K Instruct ONNX 模型生成的前 256 個令牌的平均吞吐量(tps)的改進。這些比較是在 CUDA 上,針對 FP16 和 INT4 精度進行的測量,測量裝置為一塊 A100 80GB GPU(SKU:Standard_ND96amsr_A100_v4)。

CPU 和其他裝置的效能也得到了提升。
安全性
安全指標和 RAI 與基礎 Phi-3 模型保持一致。有關更多詳情,請參閱此處。
為 Phi3 嘗試 ONNX Runtime
本部落格文章介紹了 ONNX Runtime 和 DirectML 如何最佳化 Phi-3 模型。我們提供了在 Windows 和其他平臺上執行 Phi-3 的說明,以及早期的基準測試結果。進一步的改進和效能最佳化正在進行中,敬請關注五月初發布的 ONNX Runtime 1.18 版本!
我們鼓勵您嘗試 Phi-3 並在 ONNX Runtime GitHub 倉庫中分享您的反饋!