Goodnotes 塗抹擦除功能,由 ONNX Runtime 提供支援,適用於 Windows、Web 和 Android 平臺
作者
Pedro Gómez, Emma Ning2024年11月18日

在過去的三年裡,Goodnotes 工程團隊一直致力於將成功的 iPad 筆記應用引入 Windows、Web 和 Android 等其他平臺。本文將介紹這款 2022 年度 iPad 應用如何同時為這三個平臺實現了最受歡迎的 AI 功能之一——塗抹擦除,並且所有功能都由 ONNX Runtime 提供支援。
📝 什麼是塗抹擦除?
我們都是人,都會犯錯。塗抹擦除是一個簡單的功能,它允許使用者無需使用橡皮擦,只需在已有的內容上塗抹一下即可刪除。

使用者之前寫過的任何筆記,無論寫了什麼,都可以透過簡單的塗抹手勢刪除。這個功能對使用者來說可能看起來很簡單,但從工程角度來看卻相當複雜。

這是 Goodnotes 工程團隊首次為 Windows、Web 和 Android 平臺釋出的使用人工智慧的功能,這要歸功於 ONNX Runtime,它為邊緣 AI 提供了跨平臺的高效能模型推理。該團隊為這個專案使用了內部訓練的模型,並在三個不同的平臺上進行了裝置端評估。
🔍 如何檢測塗抹手勢?
對於 Goodnotes 而言,塗抹手勢不過是文件中按照特殊模式新增的另一筆畫。筆畫必須具備以下 2 個特徵才會被視為塗抹手勢:
- 筆畫中的點數應足夠多。
- 使用 ONNX Runtime 評估的 AI 模型應將這些筆畫識別為塗抹手勢。
對於工程團隊來說,這意味著 Goodnotes 團隊每次向文件新增筆記時,都必須評估其大小和 AI 模型,以確定此新新增的筆記是否為塗抹手勢。
一旦預處理階段檢查到筆記大小超過給定閾值,接下來我們就可以遵循經典的 AI 模型評估流程,如下所示:
- 從點中提取筆記特徵。
- 使用 ONNX Runtime 評估 AI 模型。
對於特徵提取,Goodnotes 團隊會規範化筆記區域中包含的點,並將使用者手寫筆生成的一系列點轉換為浮點陣列。此過程不過是所有 AI 模型為了將使用者資料轉換為 AI 模型能夠理解的內容而遵循的經典特徵提取過程。
該專案使用的 AI 模型是基於 LSTM 的監督模型,團隊精心製作並將其部署到每個平臺,因此所有使用者即使沒有網際網路連線也可以在裝置端進行評估。
一旦這些點被表示為 AI 模型可以處理的形式,就可以使用 ONNX Runtime 並讀取模型輸出作為一個分數,從而確定最近新增的筆記是否為塗抹手勢。如果該筆畫被認為是塗抹手勢,則該筆畫下面的所有筆記都將自動刪除。
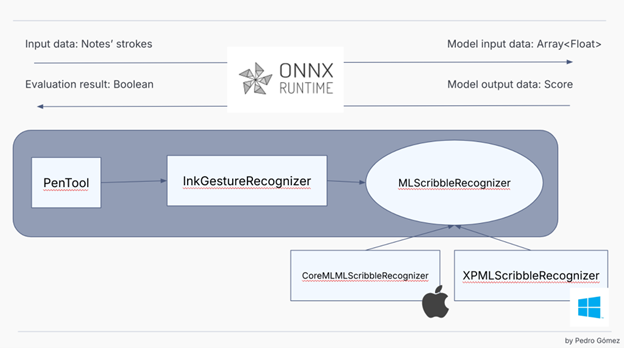
🤝 為什麼選擇 ONNX Runtime?
當 Goodnotes 團隊需要評估此功能的實現時,他們需要做出一個決定:如何評估 AI 模型。這是該專案首次使用 AI,而且該產品的 iOS 版本使用的是 CoreML,該技術與當前的專案技術棧不相容,因為這種 Apple 技術在 iOS/MacOS SDK 之外不可用。因此他們決定嘗試一些不同的東西。

Goodnotes 用於 Windows、Web 和 Android 的技術棧基於 Web 技術。在底層,該應用程式使用一個 漸進式網頁應用。當應用程式從 Microsoft Store 或 Google Play 等其他商店安裝時,應用程式使用原生封裝,但最終,該專案是一個作為全屏原生應用程式執行的 Web 應用程式。這意味著團隊用於評估 AI 模型的技術必須與 Web 技術棧相容,並且必須足夠高效能以滿足他們的需求,同時在可能的情況下啟用硬體執行時。因此,在檢查了各種替代方案後,團隊發現 ONNX 是一種可移植格式,並且 ONNX Runtime 提供了 Web 解決方案,於是決定嘗試一下。經過一些實驗和在功能實現之前使用 ONNX Runtime 建立的 原型,團隊決定這是正確的選擇!
團隊決定使用 ONNX Runtime 而非其他技術的原因有四個:
- 開發的原型 表明 ONNX Runtime 的整合對我們來說非常簡單,並提供了我們所需的所有功能。
- ONNX 是一種可移植格式,我們可以用它將當前 CoreML 模型匯出為可在多種不同作業系統上評估的格式。
- ONNX Runtime 中的執行提供程式 提供硬體加速,使我們能夠在評估模型時獲得最佳效能。具體到 Web 解決方案,它擁有針對 CPU 執行的 WSAM 執行提供程式,以及用於透過利用 GPU/NPU 進一步加速的 WebNN 和 WebGPU 執行提供程式,這些對我們來說都是非常有趣的例子。
- 與 AI 模型的 LSTM 設計相容。
💻 我們的 ONNX Runtime 程式碼是什麼樣的?
Goodnotes 團隊與 iOS/Mac 團隊共享 Goodnotes 應用程式的大部分業務邏輯程式碼。這意味著他們會編譯原始的 Swift 程式碼庫,處理筆畫,並透過 WebAssembly 對 Swift 的模型輸出進行後處理。但在執行棧中有一個點,Goodnotes 團隊必須評估模型,此時團隊會將 Swift 的執行委託給使用 ONNX Runtime 的 Web 環境。
評估模型的 TypeScript ONNX Runtime 程式碼與以下程式碼片段類似:
export class OnnxScribbleToEraseAIModel extends OnnxAIModel<Array<Array<number>>, EvaluationResult>
implements ScribbleToEraseAIModel
{
getModelResource(): OnDemandResource {
return OnDemandResource.ScribbleToErase;
}
async evaluateModel(input: Array<Array<number>>): Promise<EvaluationResult> {
const startTime = performance.now();
const { tensor, initializeTensorTime } = this.initializeTensor(input);
const { evaluationScore, evaluateModelTime } = await this.runModel(tensor);
const result = {
score: evaluationScore ?? 0.0,
timeToInitializeTensor: initializeTensorTime,
timeToEvaluateTheModel: evaluateModelTime,
totalExecutionTime: performance.now() - startTime,
};
return result;
}
…..如您所見,這個實現是任何 AI 功能都常見的經典程式碼。輸入資料以特徵陣列的形式獲取,我們稍後會使用張量將其輸入到模型中。評估完成後,我們檢查作為模型輸出獲得的分數,如果分數高於特定閾值,則認為輸入是塗抹手勢。
正如您在程式碼中看到的,除了初始化張量和評估模型外,我們還在跟蹤執行時間,以驗證我們的實現並更好地瞭解實際使用者使用此功能時在生產環境中所需的資源。
private initializeTensor(input: number[][]) {
const prepareTensorStartTime = performance.now();
const modelInput = new Float32Array(input.flat());
const tensor = new Tensor(modelInputTensorType, modelInput, modelInputDimensions);
const initializeTensorTime = performance.now() - prepareTensorStartTime;
return { tensor, initializeTensorTime };
}
private async runModel(tensor: Tensor) {
const evaluateModelStartTime = performance.now();
const inferenceSession = this.session;
const outputMap = await inferenceSession.run({ x: tensor });
const outputTensor = outputMap[modelOutputName];
const evaluationScore = outputTensor?.data[0] as number | undefined;
const evaluateModelTime = performance.now() - evaluateModelStartTime;
return { evaluationScore, evaluateModelTime };
}最重要的是,在這種情況下,Goodnotes 團隊決定使用 Web Worker 載入和評估 ONNX Runtime AI 模型,並使用 Web Worker 執行推理會話,因為應用程式中的這一路徑處於關鍵的使用者體驗流程中,我們希望最大限度地減少對使用者效能的影響。
ort.env.logLevel = 'fatal';
ort.env.wasm.wasmPaths = '/onnx/providers/wasm/';
this.session = await InferenceSession.create(modelURL);根據模型架構,本專案配置的執行提供程式是 CPU 提供程式。這是一個輕量級模型,我們可以透過預設的、由 WASM 提供支援的 CPU 執行提供程式獲得相當快的執行時間。我們計劃在新的 AI 場景中為更高階的模型提供 WebGPU 和 WebNN 執行。
🚀 部署與整合
由於團隊使用的技術棧,Web 技術的使用使得 ONNX Runtime 的整合以及我們託管 AI 模型的方式值得一提。對於本專案,Goodnotes 使用 Vite 作為前端工具,因此他們不得不稍微修改 Vite 配置,以不僅分發我們的 AI 模型,還要分發 CPU 執行提供程式所需的資源。這對團隊來說並不是一個大問題,因為 ONNX Runtime 文件已經涵蓋了打包工具的使用,但這對於他們來說相當有趣,因為應用程式是可以在離線狀態下使用的 PWA,所以這一更改增加了打包大小,不僅包括模型二進位制檔案,還包括 ONNX Runtime 所需的所有資源。
📈 生產環境執行數月後的成果
Goodnotes 在幾個月前釋出了此功能。從第一天起,所有使用者就開始透明地使用塗抹擦除模型。其中一些使用者主動開始使用塗抹手勢來刪除內容,而另一些使用者則將此功能發現為一種自然手勢。
自發布之日起,Goodnotes 團隊使用 ONNX Runtime 評估 AI 模型已將近 20 億次!使用 CPU 執行提供程式並在 Worker 中執行模型,團隊獲得了 P95 的評估時間低於 16 毫秒,P99 低於 27 毫秒的成果!世界各地的使用者,來自不同的作業系統和平臺,都已使用塗抹擦除功能修改了他們的筆記,團隊為這項出色的 ONNX Runtime 解決方案所取得的技術成就感到非常自豪!