使用 ONNX Runtime,NimbleEdge 可實現高效能裝置端即時機器學習
作者
Nilotpal Pathak, Siddharth Mittal, Scott McKay, Natalie Kershaw, Emma Ning2024 年 6 月 17 日
NimbleEdge 是一個裝置端機器學習 (ML) 平臺,可在移動應用中實現即時個性化,它在終端使用者的移動裝置上而非雲端執行資料捕獲、處理和 ML 推理。有效利用移動計算資源以在裝置資源佔用最少的情況下提供最佳效能是 NimbleEdge 的首要任務。為此,NimbleEdge 利用了各種 ML 推理執行時,其中最重要的是 ONNX Runtime。
在這篇部落格文章中,我們將探討如何在移動應用中利用裝置端計算實現經濟高效、保護隱私的即時 ML,以及 NimbleEdge 如何利用 ONNX Runtime 實現這一目標。我們還將分享 NimbleEdge 與印度最大的奇幻遊戲平臺之一(擁有數億使用者)進行裝置端部署的成果。
引言
隨著數字消費應用的演進,機器學習 (ML) 在數字體驗(包括電子商務、遊戲、娛樂等)中變得越來越核心。基於 ML 的推薦系統是這一現象的突出體現。它們減少了選擇困難,有助於提高轉化率和使用者參與度,如今在大規模應用中已很常見。
傳統上,推薦系統只利用歷史客戶行為(例如購買、瀏覽、點贊),每週、每天或每隔幾小時更新一次。然而,諸如 LinkedIn、Doordash 和 Pinterest 等開創性應用最近在推薦中融入了近即時和即時特性。這使得基於使用者幾分鐘甚至幾秒前互動的高度新鮮推薦成為可能,從而顯著提升了關鍵業務指標。
雲端即時機器學習的挑戰
然而,在雲端構建即時機器學習系統涉及幾個主要挑戰:

- 高計算成本: 即時儲存和處理會話內使用者互動資料會產生過高的雲成本
- 上市時間和複雜性: 設定用於 ML 的即時雲管道複雜,需要大量時間和開發人員資源
- 隱私風險和合規性: 使用者的會話內點選流資料必須傳送到雲伺服器進行處理,這引發了隱私問題
- 擴充套件性挑戰: 處理流量激增需要巨大的雲預留容量,或快速擴充套件,這在雲端很難實現
- 高延遲: 由於使用者移動裝置與雲端進行 API 呼叫所需的時間導致高延遲
裝置端機器學習作為替代方案
在使用者的移動裝置上執行即時 ML 進行推薦是使用雲端的一種可行替代方案。這消除了上述與雲端相關的大多數挑戰。
- 成本: 透過裝置端推理和資料處理顯著降低雲計算要求
- 隱私: 會話內使用者互動資料在裝置上處理,增強隱私保護
- 延遲: 大多數現代智慧手機都具備快速資料處理和推理計算的能力
- 擴充套件性: 輕鬆擴充套件,因為流量增加意味著有更多移動裝置可用於計算
然而,開發和維護裝置端即時 ML 系統也極其複雜,需要構建以下系統:
- 裝置端即時事件捕獲和儲存
- 裝置端特徵處理(如滾動視窗聚合)
- 雲端特徵同步
- 在各種移動裝置上適當地平衡延遲和資源利用率的 ML 推理執行。
所有這些都極其複雜且耗時,因此實現高效能的裝置端即時 ML 極具挑戰性。
NimbleEdge 與 ONNX Runtime:端到端裝置端機器學習平臺
NimbleEdge 透過端到端託管的裝置端即時 ML 平臺,幫助規避上述複雜性。該平臺加速並簡化了裝置端 ML 生命週期中的各個流程——無論是實驗、部署還是維護。
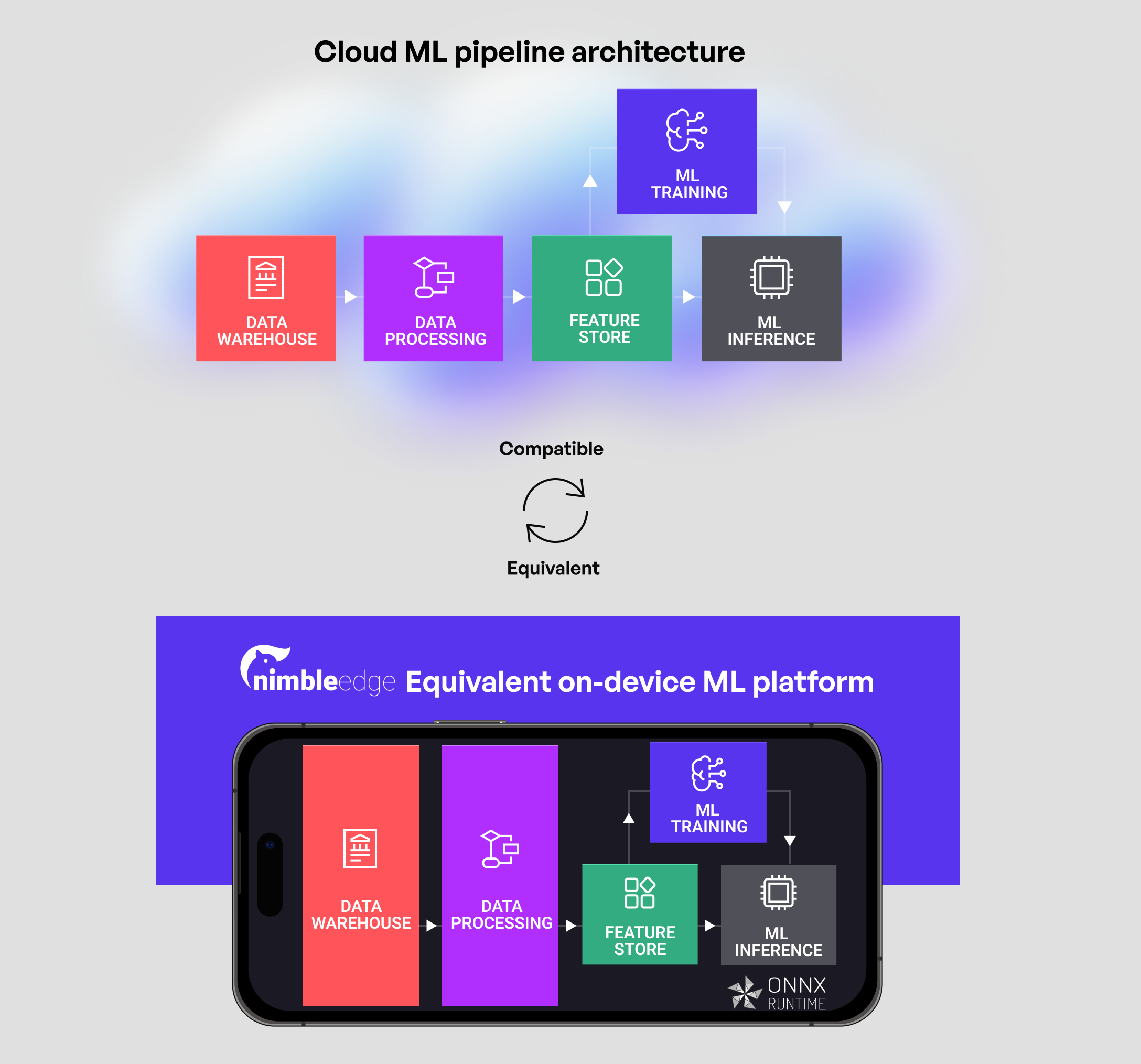
即開即用的裝置端 ML 基礎設施
- 裝置端資料倉庫: 在託管的裝置端資料庫中儲存會話內使用者事件(例如電子商務中的產品瀏覽、購物車新增),查詢延遲
< 1ms - 資料處理: 在裝置端執行類似 Python 的預處理指令碼,從即時使用者輸入中計算特徵
- 特徵儲存同步: 維護雲端特徵的裝置端副本,這些特徵用於即時 ML,並需頻繁更新(例如,美食外賣應用首頁即時餐廳排名的營業中餐廳列表)
輕鬆管理裝置端 ML 模型
- 空中下載 (OTA) 更新, 完全解耦 ML 模型更新和前端應用更新,有助於實現快速 ML 實驗
一體化、最佳化的推理執行時配置
- 部署和相容性驗證: 管理部署和相容性矩陣(例如 ML 模型、SDK 運算子、Android/iOS、NPU/GPU 等硬體能力)
- 模型效能最佳化: 透過從多執行器基礎中選擇效能最佳的推理執行時來確保最佳模型效能;為每個(裝置模型 x ML 模型)組合配置後端排程執行、並行處理、執行緒和核心數量等
用於推理執行的 ONNX Runtime
在裝置端 ML 中,最佳化推理執行至關重要。一方面,即時 ML 用例要求快速計算,以最大程度地減少終端使用者的延遲。另一方面,移動裝置資源有限,電池和處理能力受限。在當今市面上流通的 5000 多種獨特裝置型別中實現延遲和裝置資源利用率的最佳平衡,是一項巨大的挑戰。
對於推理執行,NimbleEdge 利用了多種執行時,其中最重要的是 ONNX Runtime。ONNX Runtime 是一個開源、高效能的引擎,用於在雲端和邊緣環境中加速機器學習模型。它的一個關鍵特性是 ONNX Runtime Mobile,它經過專門最佳化,可提供更輕更快地模型推理。它提供了針對量化、硬體加速(例如使用 CPU/GPU/NPU)、運算子融合、並行處理等方面的配置。NimbleEdge 以多種有效方式利用 ONNX Runtime Mobile:
- 應用靜態和動態量化技術,顯著減少模型的記憶體佔用
- 定製執行時構建,以匹配模型所需的特定運算子和資料型別
- 利用低層控制機制,精細管理和最佳化資源(CPU、電池)消耗
憑藉此處列出的能力,NimbleEdge 全面的裝置端 ML 平臺能夠將高效能即時 ML 部署從數月縮短至數天。
案例研究:印度領先奇幻遊戲公司奇幻體育競賽的即時排名
奇幻遊戲公司(出於保密原因隱去名稱)是印度一家奇幻體育平臺(類似於美國的 Fanduel/Draftkings),擁有數億使用者,峰值併發使用者數達數百萬。奇幻遊戲公司提供來自 10 多種體育專案的數千場奇幻競賽,每場競賽的參賽金額、獲勝百分比和參與者數量各不相同。
為了最佳化使用者旅程,奇幻遊戲公司正在執行一個推薦系統,根據歷史互動向使用者提供個性化的競賽推薦。他們分析了客戶點選流資料,並發現將會話內使用者互動整合到推薦系統中,將顯著提高推薦質量,優於每小時生成的批次預測。
因此,奇幻遊戲公司渴望部署即時、會話感知的推薦系統,但由於上述雲端即時 ML 的挑戰,實施起來困難重重。因此,奇幻遊戲公司轉向與 NimbleEdge 合作,利用裝置端 ML 來實現即時個性化競賽推薦。
結果
藉助 NimbleEdge,奇幻遊戲公司現在能夠根據即時使用者互動生成特徵和預測,從而提高對數百萬使用者的推薦相關性。此外,推理以毫秒級延遲交付,並且對電池和 CPU 使用率的影響極小!
推理次數: 70 億次以上
裝置崩潰次數: 0
平均延遲: 約 15 毫秒
CPU 使用率峰值: <1%
可擴充套件用例
本部落格中討論的方法也易於應用於其他垂直領域的類似即時用例——例如電子商務、社交媒體和娛樂。
電子商務:即時推薦
電子商務應用在結賬、主頁和產品頁面上提供推薦。整合會話內使用者輸入,例如頁面瀏覽量、搜尋查詢和購物車新增,可以顯著提高推薦質量。
中國電商巨頭淘寶報告稱,透過會話感知的個性化主頁推薦,GMV 增長約 10%!由於雲端即時 ML 的挑戰,阿里巴巴在裝置端部署了推薦系統,帶來了顯著的營收提升。
社交媒體:資訊流排名
社交媒體使用者的意圖在不同會話之間可能差異很大。擅長即時捕獲意圖並相應調整的社交媒體應用最終會獲得更高的使用者參與度。
例如,Pinterest 透過整合會話內使用者行為來即時定製使用者主頁,將轉發量 (Repins) 提高了 10% 以上!
結論
總之,裝置端即時 ML 的執行催生了跨領域的諸多變革性用例,帶來了巨大的營收收益。儘管執行具有挑戰性,但 NimbleEdge 和 ONNX Runtime 等工具極大地加速和簡化了實施過程,從而成為高效能即時裝置端 ML 的主要替代方案。