量化是在微調之前還是之後進行更好?
作者:
Jambay Kinley, Sam Kemp2024年11月19日
👋 引言
機器學習中的量化是一種用於降低計算中數字精度的技術,有助於提高模型的效率。量化不是使用高精度浮點數(如32位或16位),而是將這些數字轉換為低精度格式,例如8位整數。量化的主要優點是模型尺寸更小、計算速度更快,這對於在資源有限的裝置(如手機或嵌入式系統)上部署模型特別有用。然而,這種精度降低有時可能會導致模型準確性略有下降。
使用LoRA(低秩適應)方法對AI模型進行微調是一種高效地將大型語言模型適應特定任務或領域的方式。LoRA不是重新訓練所有模型引數,而是透過凍結原始模型權重並將更改應用於一組單獨的權重來修改微調過程,然後將這些權重新增到原始引數中。這種方法將模型引數轉換為較低的秩維度,減少了需要訓練的引數數量,從而加快了過程並降低了成本。
在對模型進行微調和量化時,建立正確的順序很重要。
- 量化是在微調**之前**進行更好,還是之後?
理論上,在微調之前進行量化應該能產生更好的模型,因為LoRA權重是使用它們將要部署的相同量化基礎模型權重進行訓練的。這避免了在浮點基礎權重上訓練然後使用量化基礎模型部署時發生的精度損失。在這篇博文中,我們將展示Olive(ONNX Runtime 的尖端模型最佳化工具包)如何幫助您回答何時進行量化以及針對給定模型架構和場景使用哪種量化演算法。
此外,作為回答何時進行量化問題的一部分,我們將展示以下不同的量化**演算法**如何影響準確性:
- 啟用感知權重量化 (AWQ) 是一種旨在最佳化大型語言模型 (LLM) 以實現高效執行的技術。AWQ 透過考慮推理過程中產生的啟用來量化模型的權重。這意味著量化過程會考慮啟用中實際的資料分佈,與傳統的權重量化方法相比,這有助於更好地保持模型準確性。
- 通用訓練後量化 (GPTQ) 是一種專為生成式預訓練 Transformer (GPT) 模型設計的訓練後量化技術。它將模型的權重量化到較低的位寬,例如4位整數,以減少記憶體使用和計算需求,同時不顯著影響模型的準確性。該技術獨立量化權重矩陣的每一行,以找到一個誤差最小的權重版本。
⚗️ 使用 Olive 執行實驗
為了回答關於量化和微調正確順序的問題,我們利用了 Olive (ONNX Live)——一個先進的模型最佳化工具包,旨在簡化使用ONNX Runtime部署AI模型的最佳化過程。
注意:量化和微調都需要在 Nvidia A10 或 A100 GPU 機器上執行。
1. 💾 安裝 Olive
我們使用 pip 安裝了 Olive CLI。
pip install olive-ai[finetune]
pip install autoawq
pip install auto-gptq
2. 🗜️ 量化
我們使用以下 Olive 命令,透過 AWQ 和 GPTQ 演算法對 Phi-3.5-mini-instruct 進行量化。
# AWQ Quantization
olive quantize \
--algorithm awq \
--model_name_or_path microsoft/Phi-3.5-mini-instruct \
--output_path models/phi-awq
# GPTQ Quantization
olive quantize \
--algorithm gptq \
--model_name_or_path microsoft/Phi-3.5-mini-instruct \
--data_name wikitext \
--subset wikitext-2-raw-v1 \
--split train \
--max_samples 128 \
--output_path models/phi-gptq
3. 🎚️ 微調
我們使用來自 Hugging Face 的 tiny codes 資料集對**量化後的模型**進行微調。這是一個受限資料集,您需要請求訪問許可權。獲得訪問許可權後,您應該使用訪問令牌登入 Hugging Face。
huggingface-clu login --token TOKEN
Olive 可以使用以下命令進行微調:
# Finetune AWQ model
olive finetune \
--model_name_or_path models/phi-awq \
--data_name nampdn-ai/tiny-codes \
--train_split "train[:4096]" \
--eval_split "train[4096:4224]" \
--text_template "### Language: {programming_language} \n### Question: {prompt} \n### Answer: {response}" \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--max_steps 100 \
--logging_steps 25 \
--output_path models/phi-awq-ft
# Finetune GPTQ model
olive finetune \
--model_name_or_path models/phi-gptq \
--data_name nampdn-ai/tiny-codes \
--train_split "train[:4096]" \
--eval_split "train[4096:4224]" \
--text_template "### Language: {programming_language} \n### Question: {prompt} \n### Answer: {response}" \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--max_steps 100 \
--logging_steps 25 \
--output_path models/phi-gptq-ft
注意:我們還進行了相反的順序,即先微調再進行量化。它們是相同的命令,但執行順序不同。
4. 🎯 執行困惑度評估
我們使用 Olive 對模型運行了困惑度指標評估。首先,我們在一個名為 perplexity-config.yaml 的檔案中定義了以下 Olive 配置,該配置使用了 Olive 的評估功能。
input_model:
type: HfModel
model_path: models/phi-awq-ft/model
adapter_path: models/phi-awq-ft/adapter
systems:
local_system:
type: LocalSystem
accelerators:
- device: gpu
execution_providers:
- CUDAExecutionProvider
data_configs:
- name: tinycodes_ppl
type: HuggingfaceContainer
load_dataset_config:
data_name: nampdn-ai/tiny-codes
split: 'train[5000:6000]'
pre_process_data_config:
text_template: |-
### Language: {programming_language}
### Question: {prompt}
### Answer: {response}
strategy: line-by-line
max_seq_len: 1024
dataloader_config:
batch_size: 8
evaluators:
common_evaluator:
metrics:
- name: tinycodes_ppl
type: accuracy
sub_types:
- name: perplexity
data_config: tinycodes_ppl
passes: {}
auto_optimizer_config:
disable_auto_optimizer: true
evaluator: common_evaluator
host: local_system
target: local_system
output_dir: models/eval
注意:我們為其他模型定義了相同的配置,但更新了
input_model。
然後,我們使用以下命令執行了 Olive 配置:
olive run --config perplexity-config.yaml📊 結果
Phi-3.5-Mini-Instruct
下表顯示了以下模型的困惑度指標:
- 不同的量化和微調順序(品紅色)
- Phi-3.5-Mini-Instruct 基礎模型(綠色虛線),未量化
- Phi-3.5-Mini-Instruct 微調模型(綠色實線),未量化

目標是使量化模型儘可能接近微調模型(綠色實線)。有以下幾點:
- 量化對模型質量沒有顯著影響——從量化模型的困惑度分數與微調基礎模型的接近程度可以看出。
- 在微調**之前**進行量化確實比在微調之後進行量化能產生更好的結果。
- 在此場景中,GPTQ 提供了比 AWQ 更好的準確性。
Llama-3.1-8B-Instruct
下表顯示了以下模型的困惑度指標:
- 不同的量化和微調順序(藍色)
- Llama-3.1-8B-Instruct 基礎模型(綠色虛線),未量化
- Llama-3.1-8B-Instruct 微調模型(綠色實線),未量化
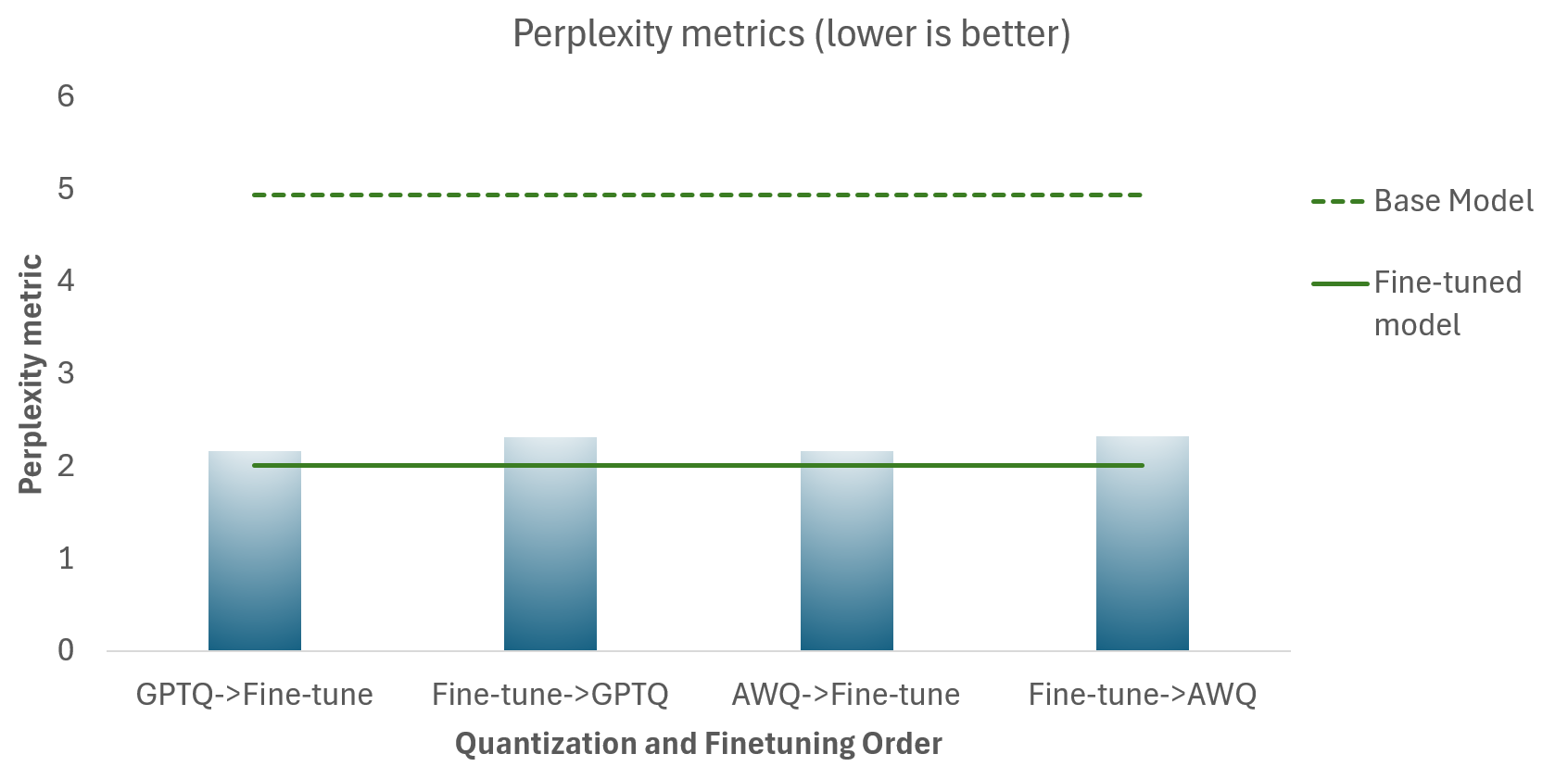
目標是使量化模型儘可能接近微調模型(綠色實線)。有以下幾點:
- 量化對模型質量沒有顯著影響——從量化模型的困惑度分數與微調基礎模型的接近程度可以看出。
- 在微調**之前**進行量化確實比在微調之後進行量化能產生更好的結果。
- GPTQ 和 AWQ 提供了相似的模型質量結果。
結論
在這篇博文中,我們展示瞭如何利用 Olive 來解決常見的 AI 模型最佳化問題。我們的研究結果表明,對於 Phi-3.5-mini-instruct 和 Llama-3.1-8B-Instruct,在微調之前進行量化可以提高模型質量。這些量化變體在記憶體和儲存佔用更少的情況下,其質量與全精度 (FP32) 對應版本非常接近。這強調了裝置端 AI 在減少資源佔用的同時提供高質量效能的潛力。