藉助 Olive 共享快取功能,在 AI 模型最佳化期間增強團隊協作
作者
Xiaoyu Zhang, Devang Patel, Sam Kemp2024年10月30日
👋 簡介
在不斷發展的機器學習領域,最佳化是提升模型效能、降低延遲和削減成本的關鍵支柱。Olive 是一款強大的工具,旨在透過其創新的共享快取功能簡化最佳化過程。
機器學習的效率不僅依賴於演算法的有效性,還依賴於所涉及過程的效率。Olive 的共享快取功能(由 Azure 儲存支援)透過無縫允許中間模型在團隊內部儲存和重用,避免了冗餘計算,從而體現了這一原則。
這篇部落格文章將透過實際示例,深入探討 Olive 的共享快取功能如何幫助您節省時間和成本。
先決條件
- 一個 Azure 儲存賬戶。有關如何建立 Azure 儲存賬戶的詳細資訊,請閱讀 建立 Azure 儲存賬戶。
- 建立 Azure 儲存賬戶後,您需要建立一個儲存容器(容器組織一組 blob,類似於檔案系統中的目錄)。有關如何建立儲存容器的更多詳細資訊,請閱讀 建立容器。
🤝 最佳化過程中的團隊協作
使用者A透過使用 Olive 的量化命令,採用 AWQ 演算法最佳化 Phi-3-mini-4k-instruct 模型,開始最佳化過程。此步驟透過以下命令列執行:
olive quantize \
--model_name_or_path Microsoft/Phi-3-mini-4k-instruct \
--algorithm awq \
--account_name {AZURE_STORAGE_ACCOUNT} \
--container_name {STORAGE_CONTAINER_NAME} \
--log_level 1
注意
--account_name應設定為您的 Azure 儲存賬戶名稱。--container_name應設定為 Azure 儲存賬戶中的容器名稱。
最佳化過程會生成一條日誌,確認快取已儲存到 Azure 的共享位置。
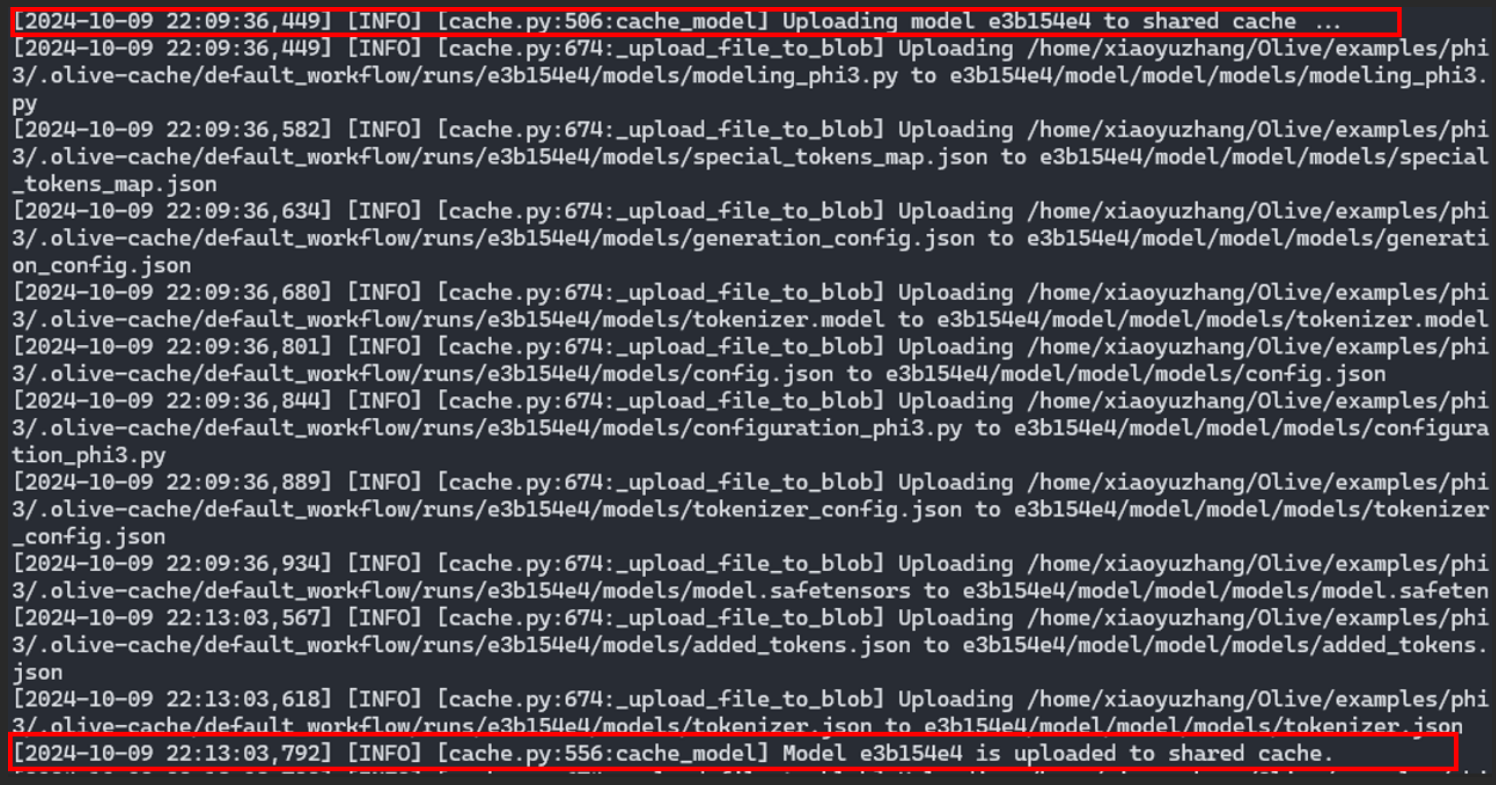 來自使用者A的 Olive 日誌輸出:使用者A工作流中的量化模型已上傳到雲端的共享快取中。
來自使用者A的 Olive 日誌輸出:使用者A工作流中的量化模型已上傳到雲端的共享快取中。這個共享快取是一個關鍵元素,因為它儲存了最佳化後的模型,使其可供其他使用者或程序將來使用。
利用共享快取
使用者B,作為最佳化專案中的另一個活躍團隊成員,受益於使用者A的努力。透過使用相同的量化命令,利用 AWQ 演算法最佳化 Phi-3-mini-4k-instruct,使用者B的流程顯著加快。該命令是相同的,使用者B利用相同的 Azure 儲存賬戶和容器。
olive quantize \
--model_name_or_path Microsoft/Phi-3-mini-4k-instruct \
--algorithm awq \
--account_name {AZURE_STORAGE_ACCOUNT} \
--container_name {STORAGE_CONTAINER_NAME} \
--log_level 1
此步驟的關鍵部分是以下日誌輸出,它強調從共享快取中檢索量化模型,而不是重新計算 AWQ 量化。
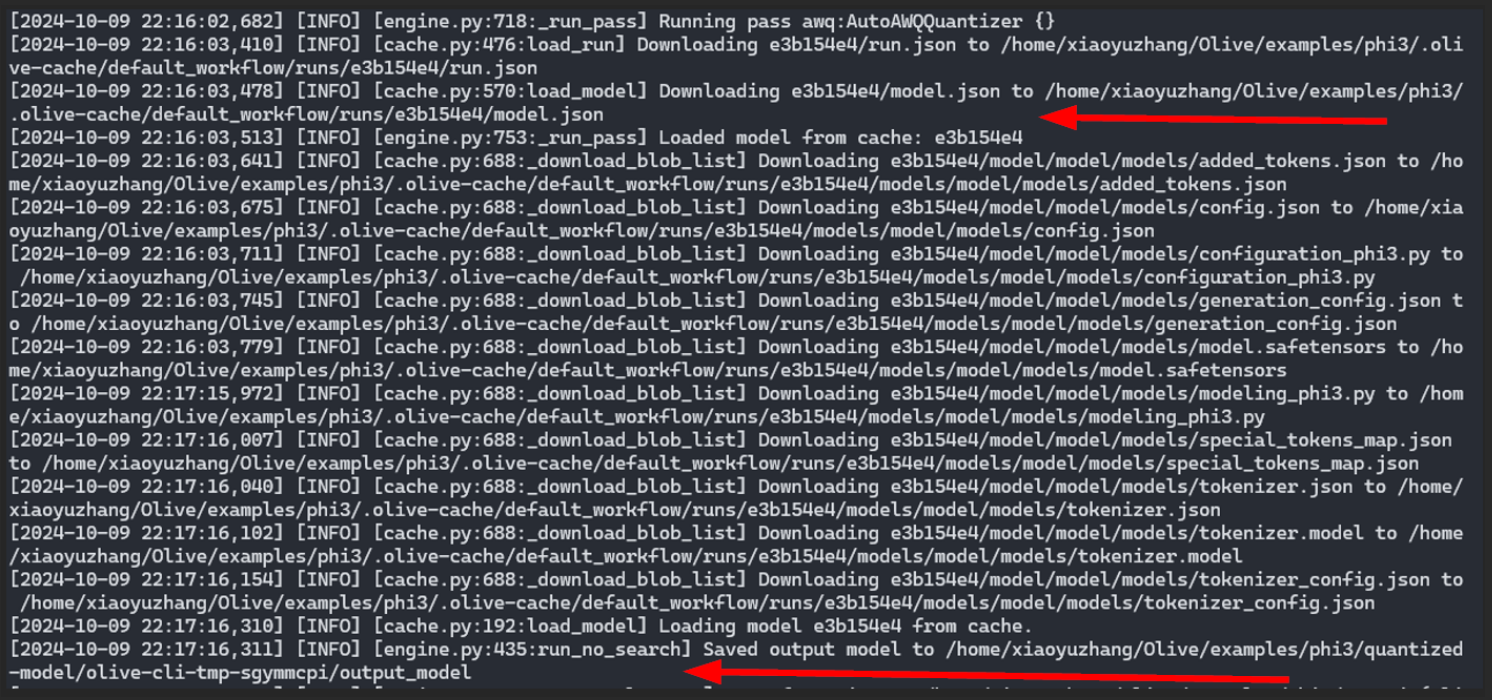 來自使用者B的 Olive 日誌輸出:使用者A工作流中的量化模型已下載並在使用者B的工作流中使用,無需重新計算。
來自使用者B的 Olive 日誌輸出:使用者A工作流中的量化模型已下載並在使用者B的工作流中使用,無需重新計算。這種機制不僅節省了計算資源,還大大縮短了最佳化所需的時間。 Azure 中的共享快取充當預最佳化模型的儲存庫,可供重用,從而提高了效率。
🪄 共享快取 + 自動最佳化器
最佳化不僅限於量化。Olive 的自動最佳化器透過在單個命令中執行進一步的預處理和最佳化任務來擴充套件其功能,以找到在質量和效能方面最佳的模型。自動最佳化器中執行的典型最佳化任務是:
- 從 Hugging Face 下載模型
- 將模型結構捕獲到 ONNX 圖中,並將權重轉換為 ONNX 格式。
- 最佳化 ONNX 圖(例如,融合、壓縮)
- 為目標硬體應用特定的核心最佳化
- 量化模型權重
使用者A利用自動最佳化器最佳化 Llama-3.2-1B-Instruct 以用於 CPU。此任務的命令列指令是:
olive auto-opt \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path optimized-model \
--device cpu \
--provider CPUExecutionProvider \
--precision int4 \
--account_name {AZURE_STORAGE_ACCOUNT} \
--container_name {STORAGE_CONTAINER_NAME} \
--log_level 1
對於自動最佳化器中執行的每個任務(例如,模型下載、ONNX 轉換、ONNX 圖最佳化、量化等),中間模型都將儲存在共享快取中,以便在不同的硬體目標上重用。例如,如果使用者B稍後希望為不同的目標(例如,Windows 裝置的 GPU)最佳化同一模型,他們將執行以下命令:
olive auto-opt \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path optimized-model \
--device gpu \
--provider DmlExecutionProvider \
--precision int4 \
--account_name {AZURE_STORAGE_ACCOUNT} \
--container_name {STORAGE_CONTAINER_NAME} \
--log_level 1
使用者A的CPU最佳化中的常見中間步驟——例如 ONNX 轉換和 ONNX 圖最佳化——將被重用,這將節省使用者B的時間和成本。
這突顯了 Olive 的多功能性,不僅體現在最佳化不同模型上,還體現在應用各種演算法和匯出器上。共享快取再次發揮關鍵作用,儲存這些最佳化後的中間模型以供後續使用。
➕ Olive 共享快取功能的優勢
上述示例展示了 Olive 的共享快取是模型最佳化領域的一項變革性功能。以下是主要優勢:
- 時間效率:透過儲存最佳化後的模型,共享快取消除了重複最佳化的需要,大大縮短了時間消耗。
- 成本降低:計算資源成本高昂。透過最大限度地減少冗餘過程,共享快取降低了相關成本,使機器學習更加經濟實惠。
- 資源最佳化:高效利用計算能力可帶來更好的資源管理,確保資源可用於其他關鍵任務。
- 協作:共享快取促進了協作環境,不同使用者可以從彼此的最佳化工作中受益,從而促進知識共享和團隊合作。
結論
透過儲存和重用最佳化後的模型,Olive 的共享快取功能為更高效、更具成本效益和協作性的環境鋪平了道路。隨著 AI 的不斷發展和演進,Olive 這樣的工具將在推動創新和提高效率方面發揮重要作用。無論您是經驗豐富的資料科學家還是該領域的新手,擁抱 Olive 都可以顯著提升您的工作流程。透過減少模型最佳化所需的時間和成本,您可以專注於真正重要的事情:開發突破性的 AI 模型,突破可能的邊界。立即開始您的 Olive 最佳化之旅,體驗機器學習效率的未來。
⏭️ 嘗試 Olive
要嘗試使用共享快取功能進行量化和自動最佳化器命令,請執行以下 pip 安裝:
pip install olive-ai[auto-opt,shared-cache] autoawq使用 AWQ 演算法量化模型需要 CUDA GPU 裝置。如果您只能訪問 CPU 裝置,並且沒有 Azure 訂閱,則可以使用 CPU 執行自動最佳化器,並使用本地磁碟作為快取:
olive auto-opt \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path optimized-model \
--device cpu \
--provider CPUExecutionProvider \
--precision int4 \
--log_level 1