使用 ONNX Runtime 加速 Phi-2、CodeLlama、Gemma 及其他生成式 AI 模型
作者
Parinita Rahi, Sunghoon Choi, Yufeng Li, Kshama Pawar, Ashwini Khade, Ye Wang2024 年 2 月 26 日
在速度和效率至關重要的快速發展環境中,ONNX Runtime (ORT) 允許使用者輕鬆地將生成式 AI 模型的強大功能整合到其應用程式和服務中,並透過最佳化的方式,實現更快的推理速度並有效降低成本。這些最佳化包括最先進的融合和核心最佳化,有助於提升模型效能。最近釋出的 ONNX Runtime 1.17 版本提升了包括 Phi-2、Mistral、CodeLlama、Orca-2 等在內的多個生成式 AI 模型的推理效能。ONNX Runtime 是一個從訓練到推理的完整小型語言模型 (SLM) 解決方案,與其他框架相比顯示出顯著的加速。透過支援 float32、float16 和 int4,ONNX Runtime 的推理增強功能提供了最大的靈活性和效能。
在這篇部落格中,我們將介紹針對 Phi-2、Mistral、CodeLlama、SD-Turbo、SDXL-Turbo、Llama2 和 Orca-2 等最新生成式 AI 模型在訓練和推理方面的顯著最佳化加速。對於這些模型架構,與 PyTorch 和 Llama.cpp 等其他框架相比,ONNX Runtime 在各種批處理大小和提示長度下都顯著提高了效能。這些使用 ONNX Runtime 的最佳化現在也可以透過 Olive 獲得。
快速連結
Phi-2
Phi-2 是一個由微軟開發的擁有 27 億引數的 Transformer 模型。它是一個小型語言模型 (SLM),展現出卓越的推理和語言理解能力。Phi-2 體積小巧,是研究人員探索機械可解釋性、安全性改進以及針對不同任務進行微調實驗等各個方面的絕佳平臺。
ONNX Runtime 1.17 引入了支援 Phi-2 模型的核心更改,包括針對 Phi-2 的 Attention、Multi-Head Attention、Grouped-Query Attention 和 RotaryEmbedding 的最佳化。具體而言,已新增對以下功能的支援:
- Multi-Head Attention CPU 核心中的因果掩碼
- Attention 和 Rotary Embedding 核心中的 rotary_embedding_dim
- Grouped-Query Attention 核心中的 bfloat16
支援基於 TorchDynamo 的 Phi-2 ONNX 匯出,並且最佳化指令碼在此基礎上構建。
對於 Phi-2 推理,使用 float16 和 int4 量化的 ORT 在所有提示長度下都比使用 float32 的 ORT、PyTorch 和 Llama.cpp 表現更好。
推理
ORT 在 float16 下的效能提升
經過最佳化的 CUDA 在提示吞吐量(即模型根據輸入提示處理和生成響應的速度)方面比 PyTorch Compile 快 高達 7.39 倍。我們還觀察到,與 Llama.cpp 相比,ONNX Runtime 在更大的批處理大小和提示長度下顯著更快。例如,在批處理大小為 16、提示長度為 2048 時,它快 高達 13.08 倍。
令牌生成吞吐量是生成的前 256 個令牌的平均吞吐量。使用 float16 的 ONNX Runtime 平均比 torch.compile 快 6.6 倍,最高可達 18.55 倍。它也比 Llama.cpp 快 高達 1.64 倍。
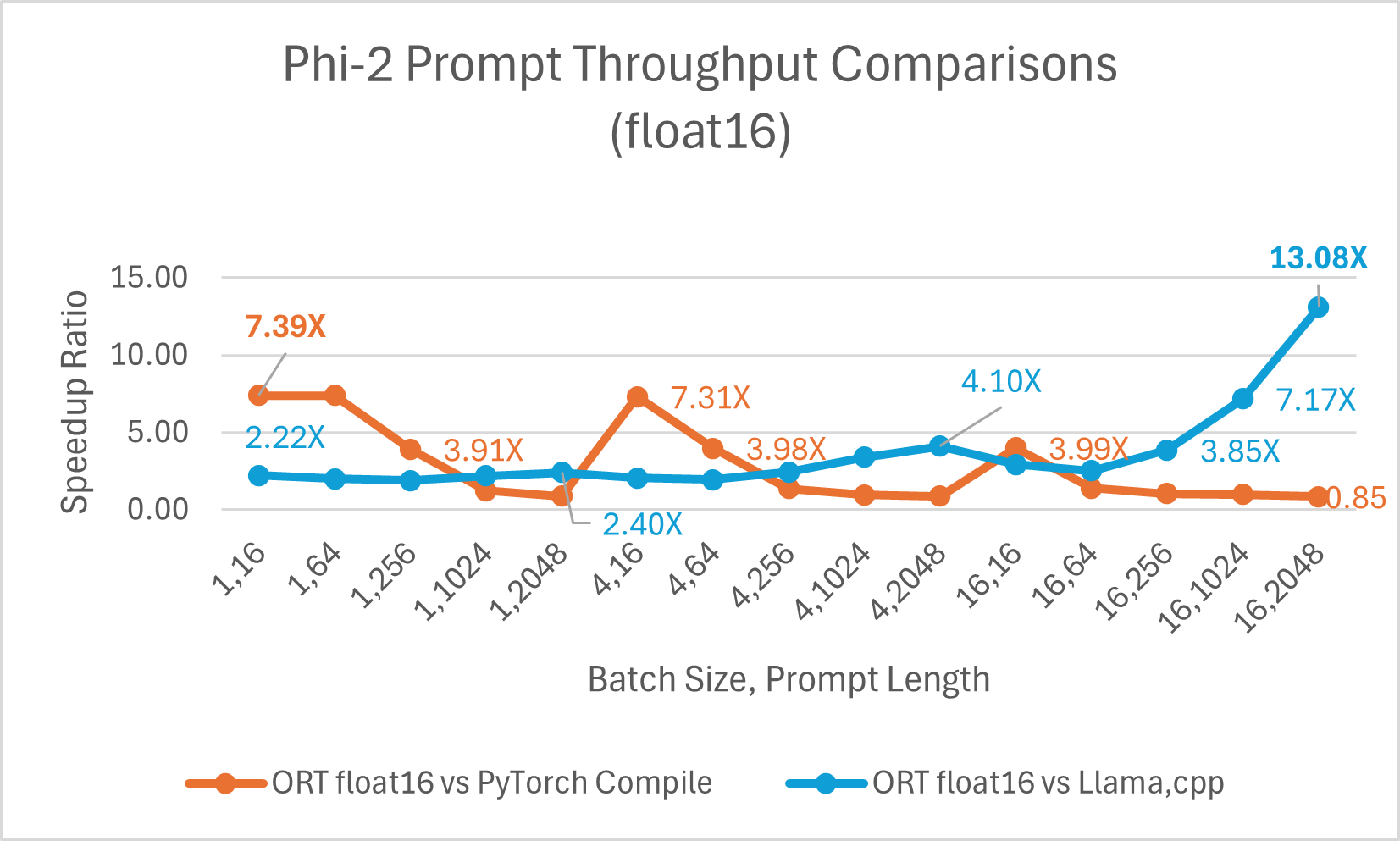
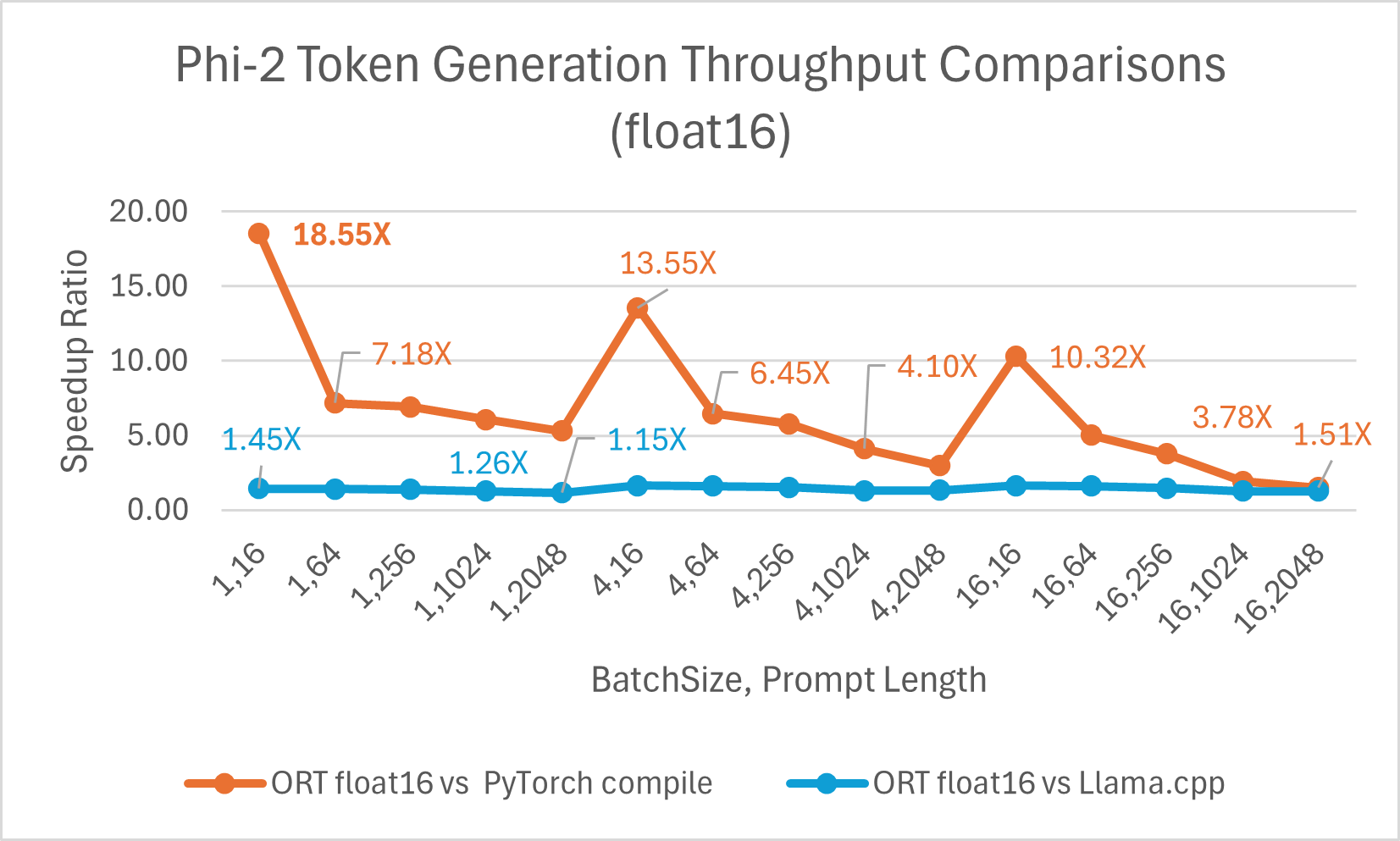
ORT 在 int4 下的效能提升
ORT 支援 int4 量化。與 PyTorch 相比,使用 int4 量化的 ORT 效能可提升 高達 20.48 倍。它平均比 Llama.cpp 好 3.9 倍,對於大序列長度,快 高達 13.42 倍。由於 GemV 的特殊核心,使用 int4 量化的 ONNX Runtime 通常在批處理大小為 1 時表現最佳。
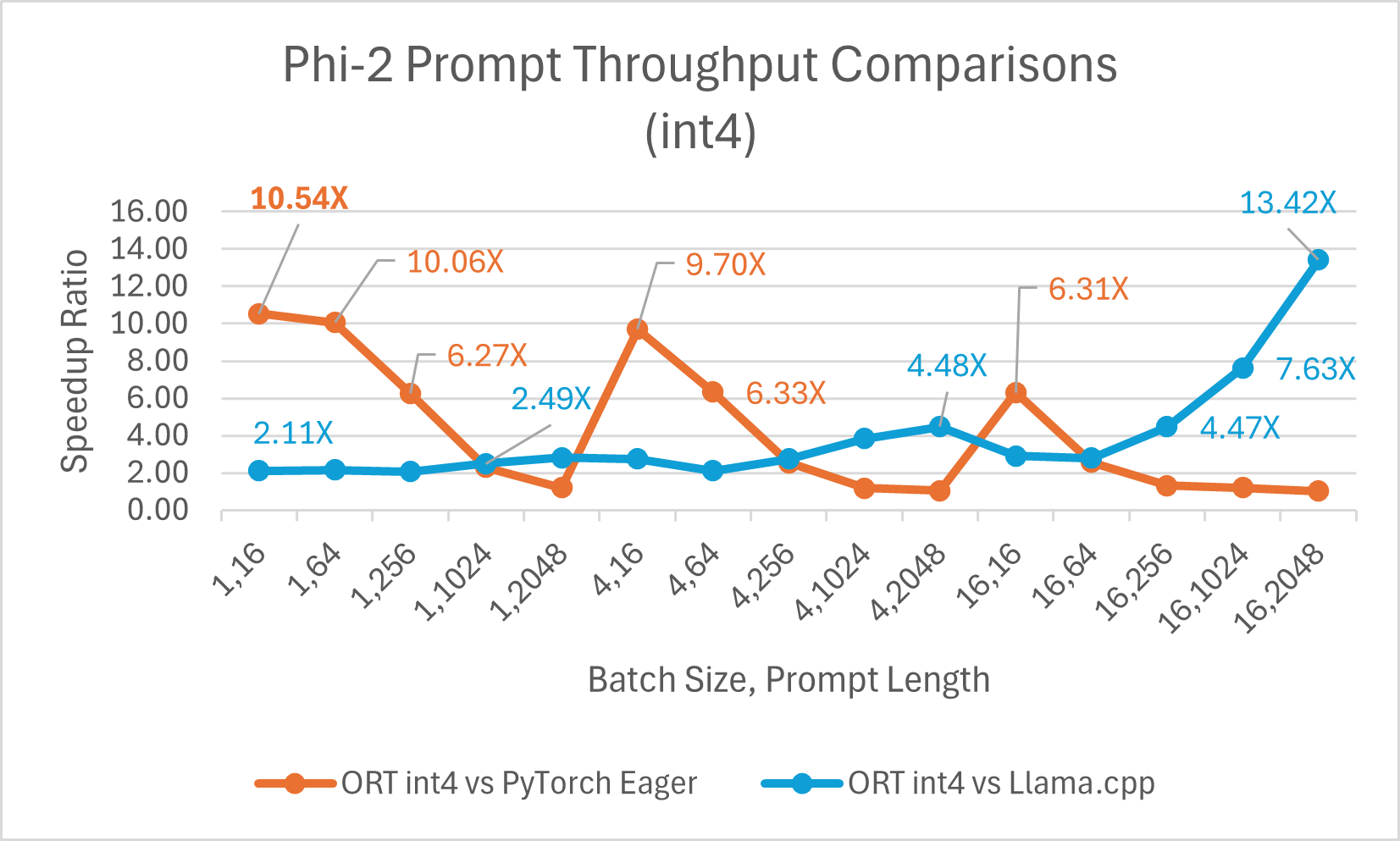
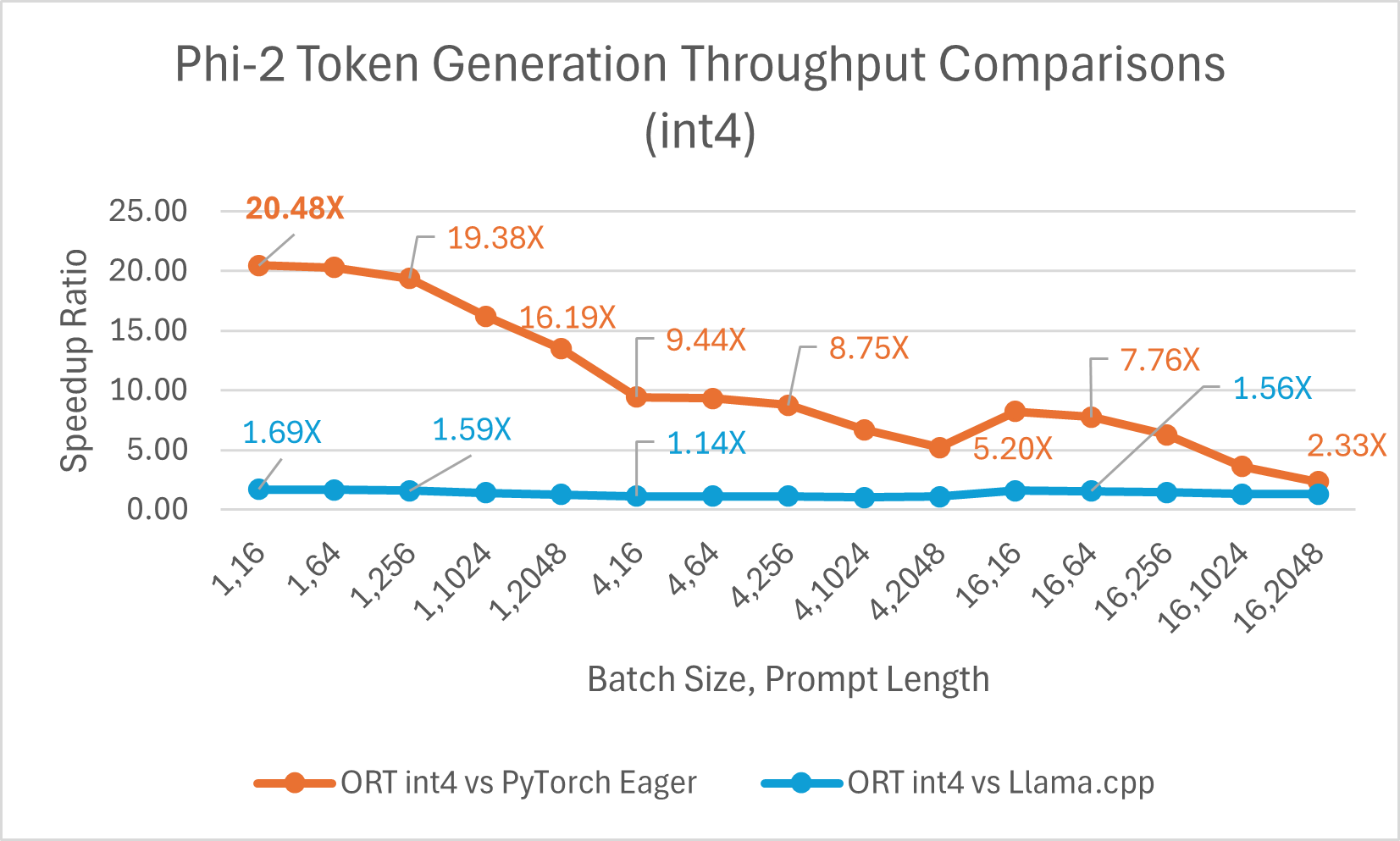
- Phi-2 基準測試在 1 塊 A100 GPU 上進行 (SKU: Standard_ND96amsr_A100_v4)。使用的軟體包:torch: 2.3.0. dev20231221+cu121; pytorch-triton: 2.2.0+e28a256d71; ort-nightly-gpu: 1.17.0.dev20240118001; deepspeed: 0.12
- 批處理是一組不同長度的輸入句子;提示長度指輸入文字的大小或長度。
這是使用 Olive 對 Phi-2 進行最佳化的示例,它利用本部落格中強調的 ONNX Runtime 最佳化,並使用易於使用的硬體感知模型最佳化工具 Olive。
訓練
除了推理,ONNX Runtime 還為 Phi-2 和其他大型語言模型 (LLM) 提供訓練加速。ORT 訓練是 PyTorch 生態系統的一部分,可透過 torch-ort python 包作為 Azure Container for PyTorch (ACPT) 的一部分提供。它提供靈活且可擴充套件的硬體支援,同一模型和 API 可與 NVIDIA 和 AMD GPU 配合使用。ORT 透過最佳化的核心和記憶體最佳化來加速訓練,這在減少大型模型訓練的端到端訓練時間方面顯示出顯著的收益。這涉及到修改模型中的幾行程式碼,以使用 ORTModule API 對其進行封裝。它還可以與 DeepSpeed 和 Megatron 等流行的加速庫組合使用,以實現更快、更高效的訓練。
Open AI 的 Triton 是一種領域特定語言和編譯器,用於編寫高效的自定義深度學習原語。ORT 支援 Open AI Triton 整合 (ORT+Triton),其中所有逐元素運算子都轉換為 Triton ops,並且 ORT 在 Triton 中建立自定義融合核心。
ORT 還執行稀疏性最佳化,以評估輸入資料的稀疏性並利用這種稀疏性進行圖最佳化。這減少了計算 FLOP 要求並提高了效能。
基於低秩介面卡 (LoRA) 的微調透過僅訓練少量額外引數(介面卡)同時凍結原始模型的權重,使訓練更高效。這些介面卡使模型適應特定任務。量化和 LoRA (QLoRA) 將量化與 LoRA 結合,其中權重使用更少的位數表示,同時保留模型的效能和質量。ONNX Runtime 訓練與 LoRA 和 QLoRA 結合,為 LLM 提供記憶體效率和訓練時間加速的收益。LoRA 和 QLoRA 技術使 LLM 等超大型模型能夠適應 GPU 記憶體,從而高效完成訓練。
使用 ORT 訓練的 Phi-2 模型與 PyTorch Eager 模式和 torch.compile 相比顯示出效能提升。Phi-2 使用合成和網路資料集的混合進行訓練。我們測量了與 ORT 和 ORT+Triton 模式的效能提升,並且隨著批處理大小的增加,提升也隨之增加。該模型使用 DeepSpeed Stage-2 訓練了 5 個 epoch,在 wikitext 資料集上使用遞增的批處理大小。V100 和 A100 的效能提升總結在下面的圖表中。
訓練基準測試在 8 塊 V100 上執行,並測量了每秒迭代次數的吞吐量(越高越好)

以下訓練基準測試在 2 塊 A100 上執行,並測量了每秒迭代次數的吞吐量(越高越好)
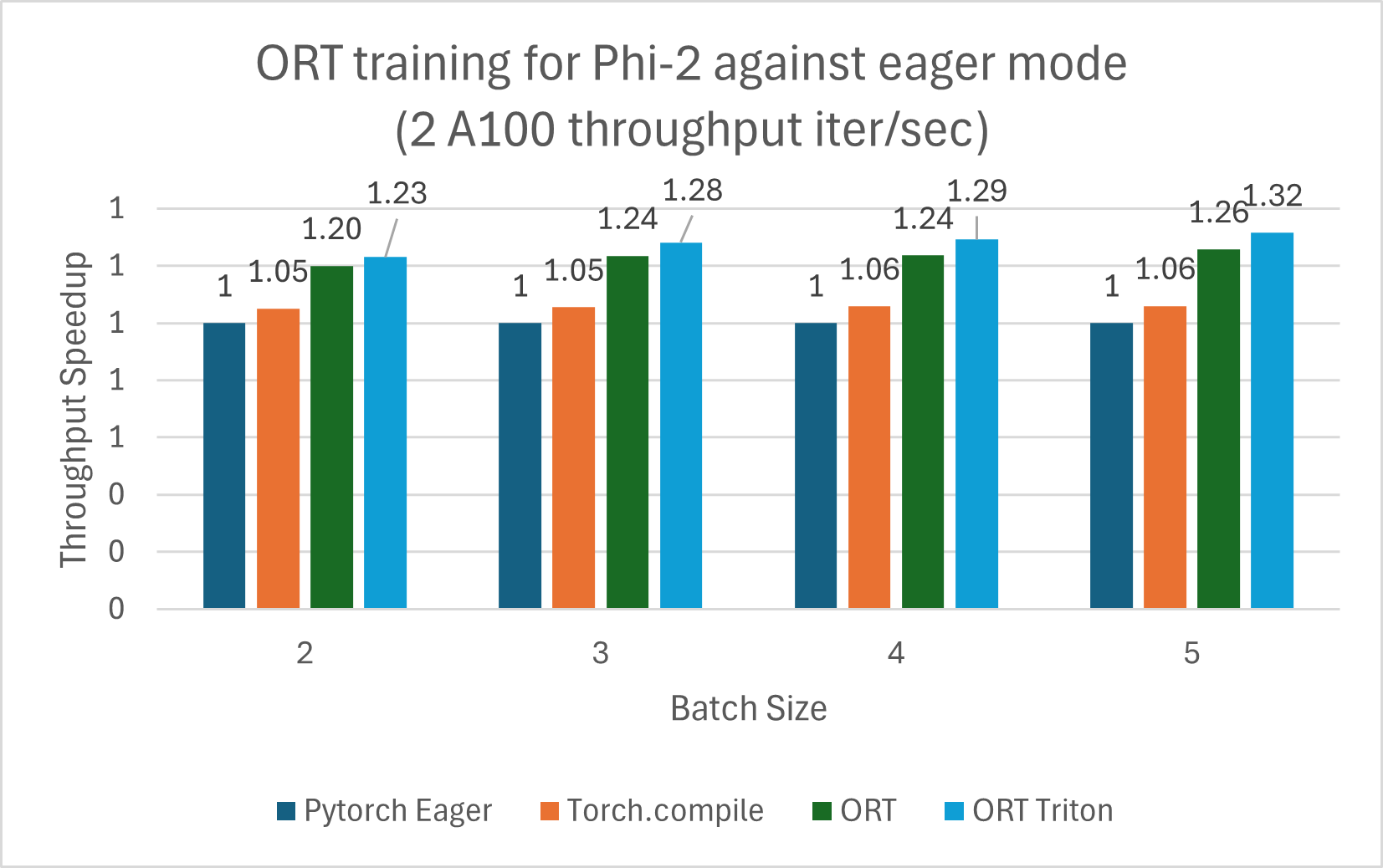 注:使用了 PyTorch Stable 2.2.0 和 ONNXRuntime Training: Stable 1.17.0 版本。
注:使用了 PyTorch Stable 2.2.0 和 ONNXRuntime Training: Stable 1.17.0 版本。 Mistral
推理
Mistral7B 是一個預訓練的生成式文字大型語言模型 (LLM),擁有 70 億引數。ONNX Runtime 顯著提升了 Mistral 在 float16 和 int4 模型下的推理效能。使用 float16 時,ONNX Runtime 比 Llama.cpp 快 高達 9.46 倍。對於批處理大小為 1 的 int4 量化,令牌生成吞吐量顯著提高,比 PyTorch Eager 快 高達 18.25 倍。
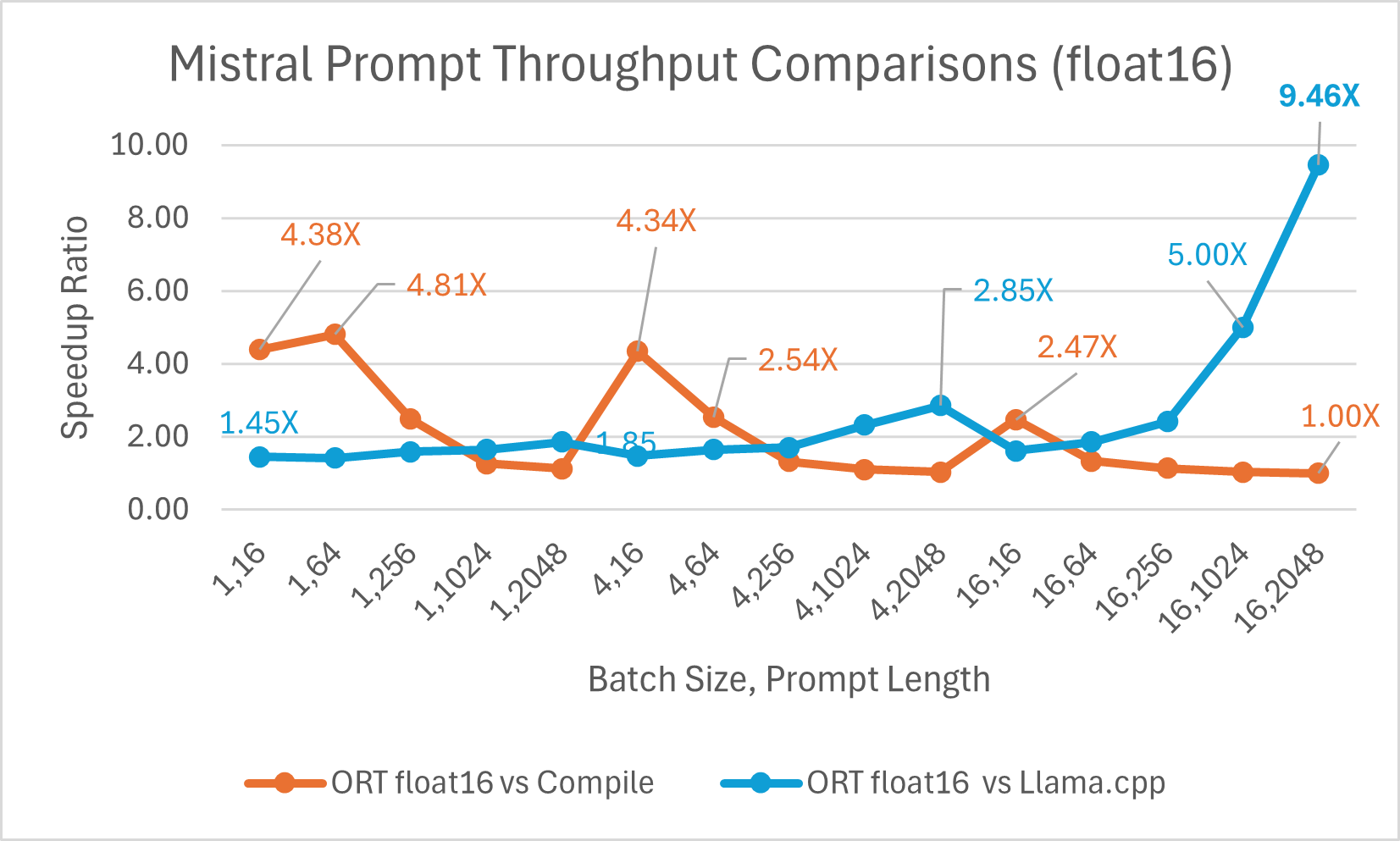

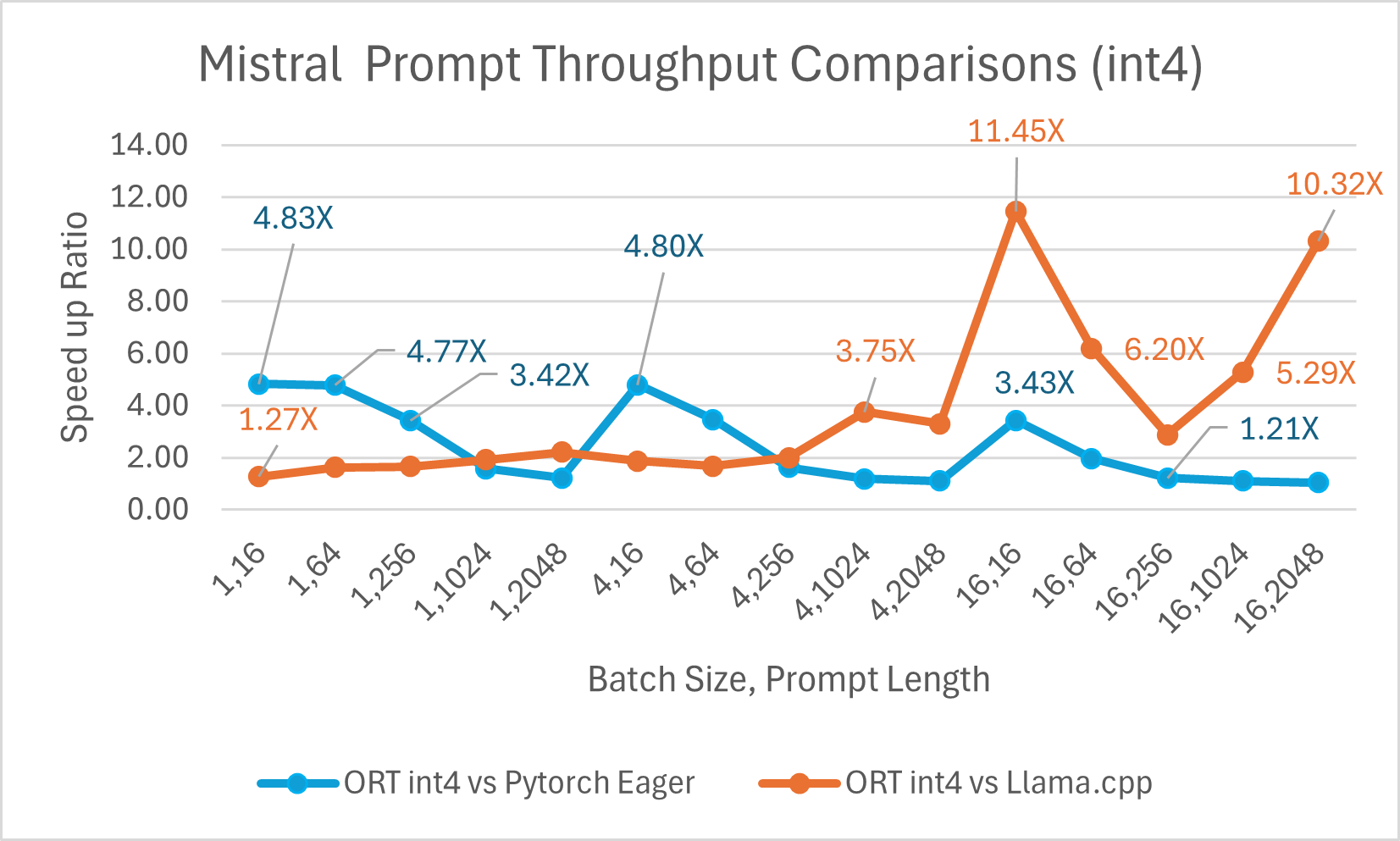
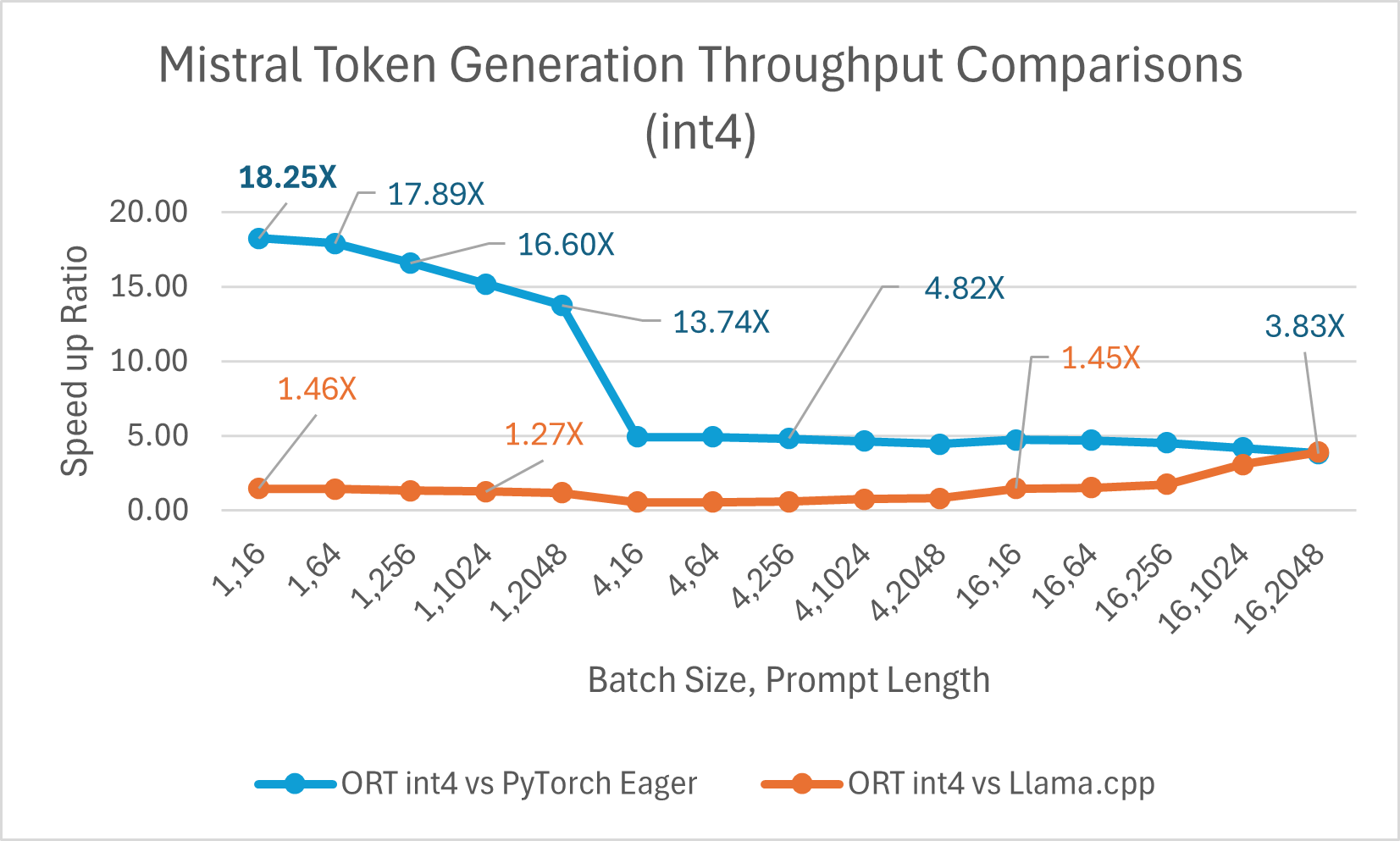
您現在可以在 Huggingface 這裡獲取最佳化後的 Mistral 模型。
訓練
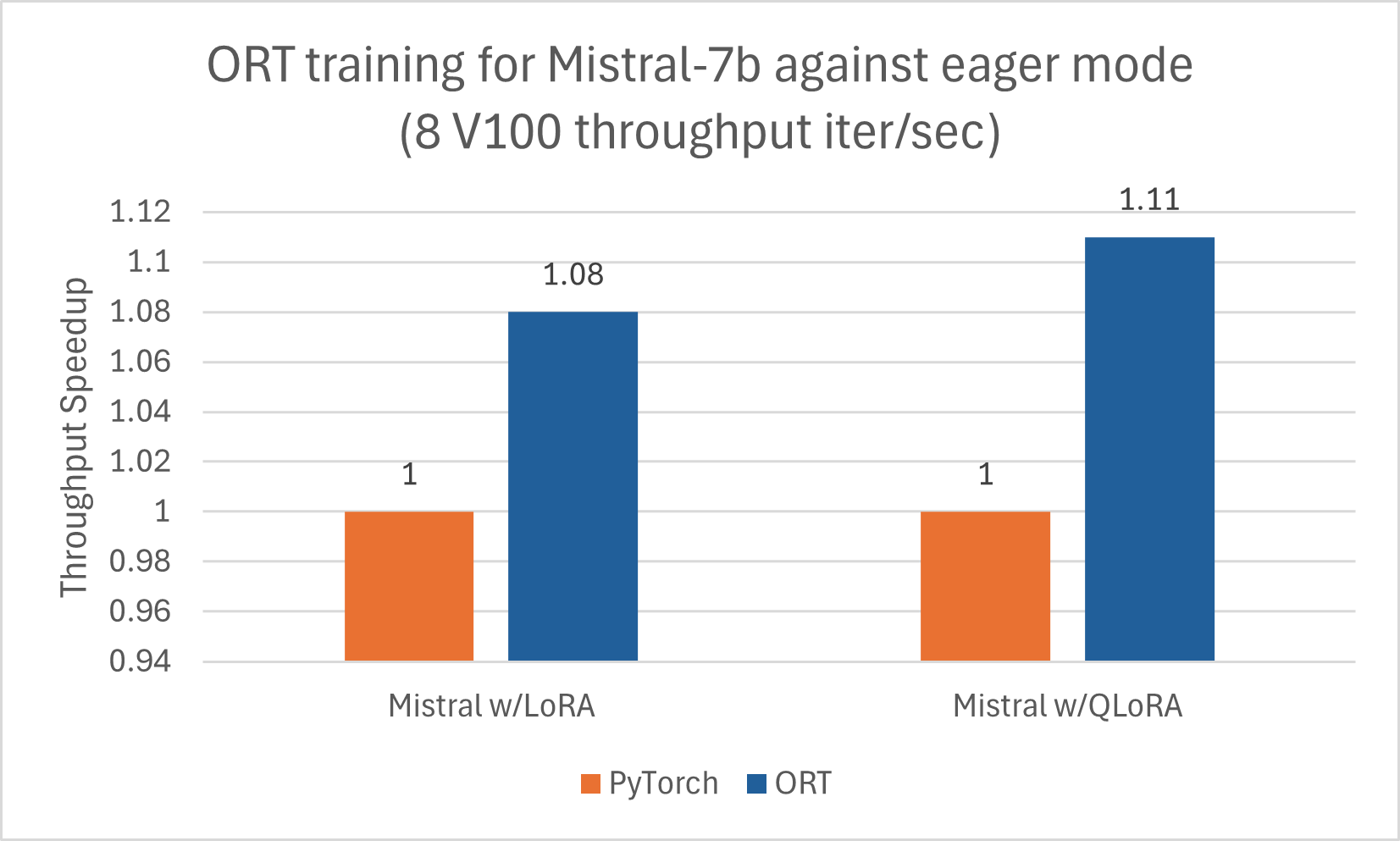
與 Phi-2 類似,Mistral 也受益於使用 ORT 進行訓練加速。我們使用以下配置訓練了 Mistral-7B,以觀察 ORT 的效能提升,包括與 LoRA 和 QLoRA 結合使用時。該模型使用 DeepSpeed Stage-2 訓練了 5 個 epoch,在 wikitext 資料集上使用批處理大小 1。
CodeLlama
Codellama-70B 是一個基於 Llama-2 平臺開發的專注於程式設計的模型。該模型可以生成程式碼並以自然語言圍繞程式碼進行討論。由於 CodeLlama-70B 是一個經過微調的 Llama 模型,因此可以直接應用現有的最佳化。我們將一個 4 位量化的 ONNX 模型與 PyTorch Eager 和 Llama.cpp 進行了比較。對於提示吞吐量,ONNX Runtime 在所有批處理大小下都比 PyTorch Eager 至少快 1.4 倍。ONNX Runtime 生成令牌的平均速度比 PyTorch Eager 在任何批處理大小下都高 3.4 倍,比 Llama.cpp 在批處理大小為 1 時高 1.5 倍。


SD-Turbo 和 SDXL-Turbo
ONNX Runtime 在與 SD Turbo 和 SDXL Turbo 結合使用時提供了推理效能優勢,並且還使得這些模型可以在 Python 之外的語言中(如 C# 和 Java)訪問。在所有評估的(批處理大小,步數)組合中,ONNX Runtime 的吞吐量均高於 PyTorch,其中 SDXL Turbo 模型的吞吐量提升高達 229%,SD Turbo 模型提升120%。ONNX Runtime CUDA 在處理動態形狀方面表現尤為出色,同時在靜態形狀方面也顯示出相對於 PyTorch 的顯著優勢。
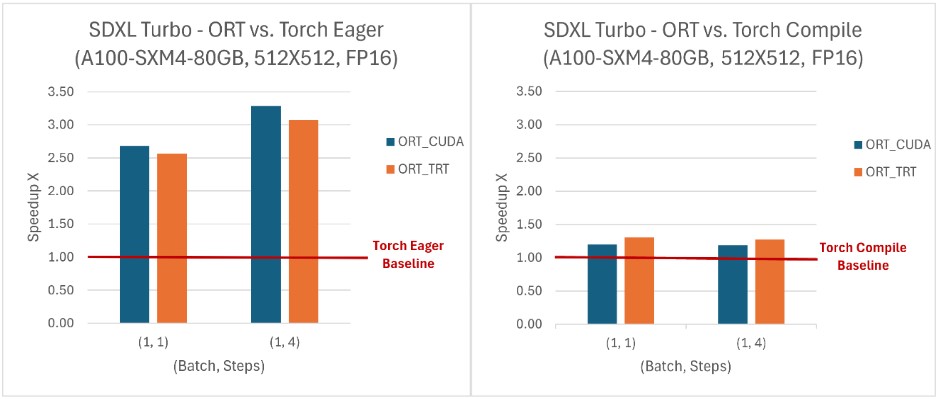
要了解更多關於使用 ONNX Runtime 加速 SD-Turbo 和 SDXL-Turbo 推理的資訊,請檢視我們最近與 Hugging Face 合作釋出的部落格。
Llama-2
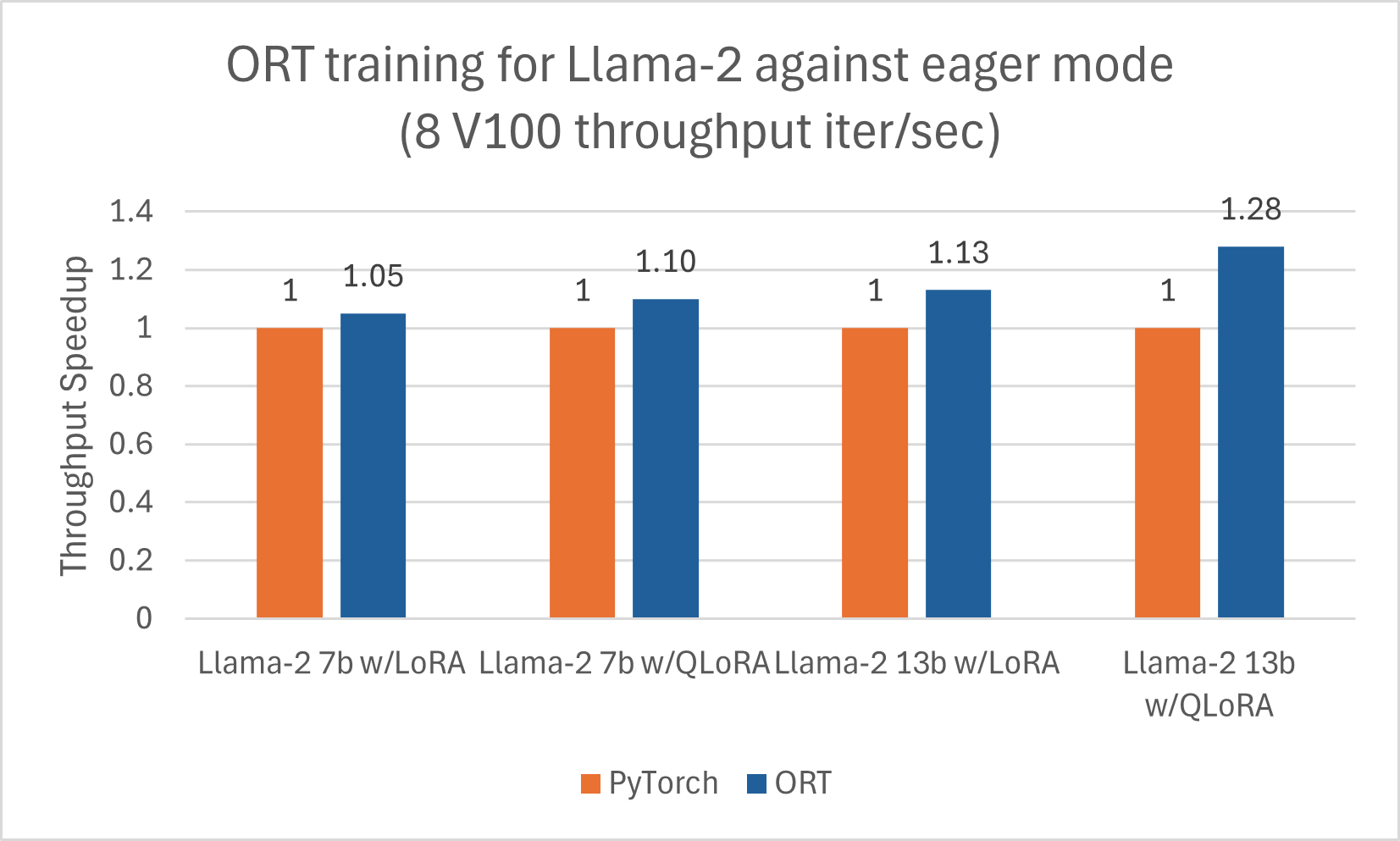
我們釋出了另一篇部落格,詳細介紹了使用 ORT 對 Llama-2 進行推理的改進這裡。此外,Llama-2-7B 和 Llama-2-13B 在使用 ORT 進行訓練時顯示出良好的效能提升,尤其是在與 LoRA 和 QLoRA 結合使用時。這些指令碼可以作為使用 Optimum 和 ORT 微調 Llama-2 的示例。以下資料是 Llama-2 模型使用 DeepSpeed Stage-2 進行 5 個 epoch 訓練,批處理大小為 1,在 wikitext 資料集上的結果。
Orca-2
推理
Orca-2 是一個僅用於研究的系統,可在處理使用者提供的資料推理、文字理解、數學問題求解和文字摘要等任務中提供一次性答案。Orca-2 有兩個版本(70 億和 130 億引數);兩者都是透過在定製的、高質量的人工資料上微調各自的 Llama-2 基礎模型而製成的。ONNX Runtime 透過使用圖融合和核心最佳化(如 Llama-2 的最佳化)來幫助最佳化 Orca-2 推理。
ORT 在 int4 下的效能提升
Orca-2-7B int4 量化效能比較顯示,與 PyTorch 相比,提示吞吐量效能提升高達 26 倍,令牌生成吞吐量提升高達 16.5 倍。與 Llama.cpp 相比,提示吞吐量提升超過 4.75 倍,令牌生成吞吐量提升 3.64 倍。
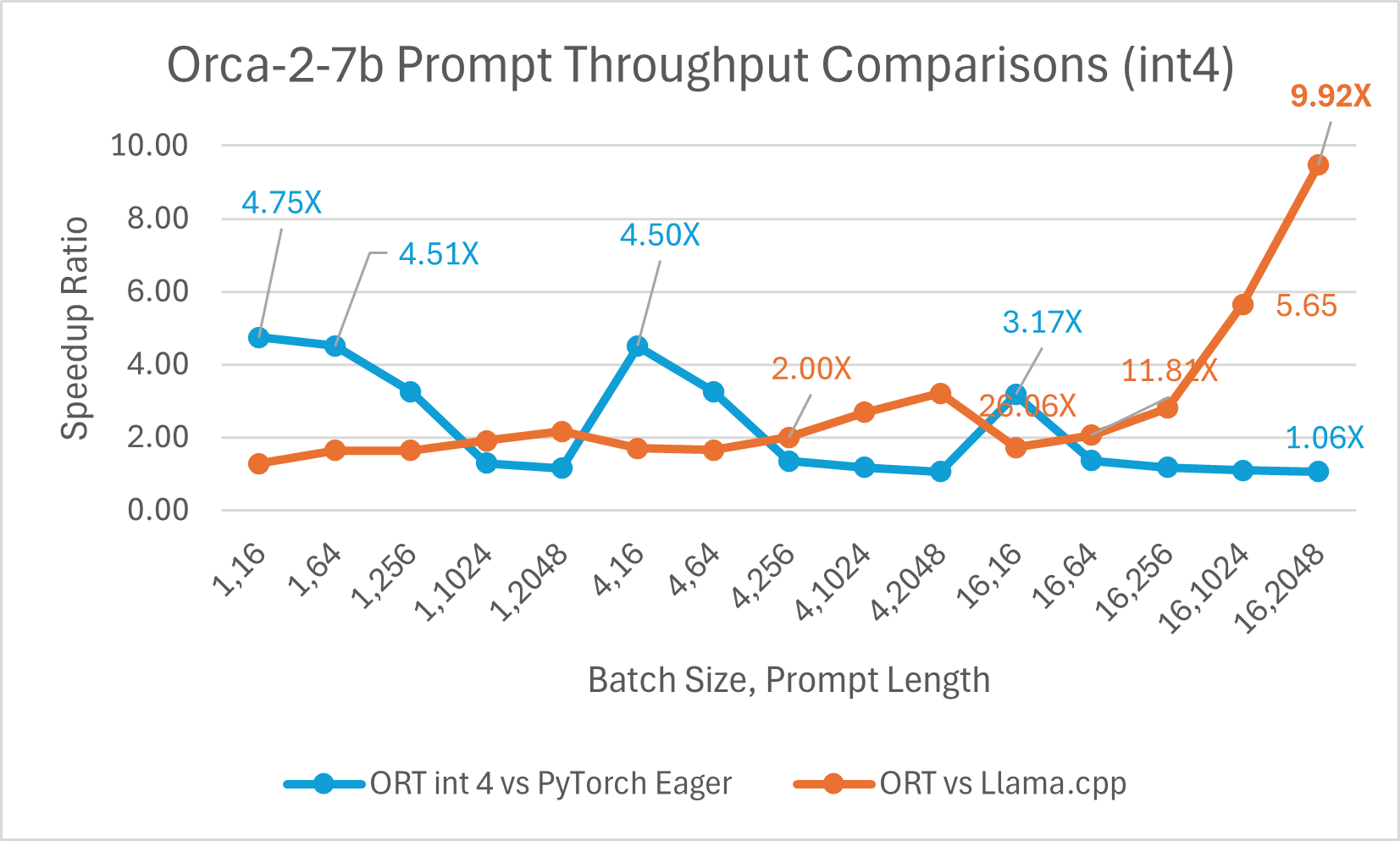
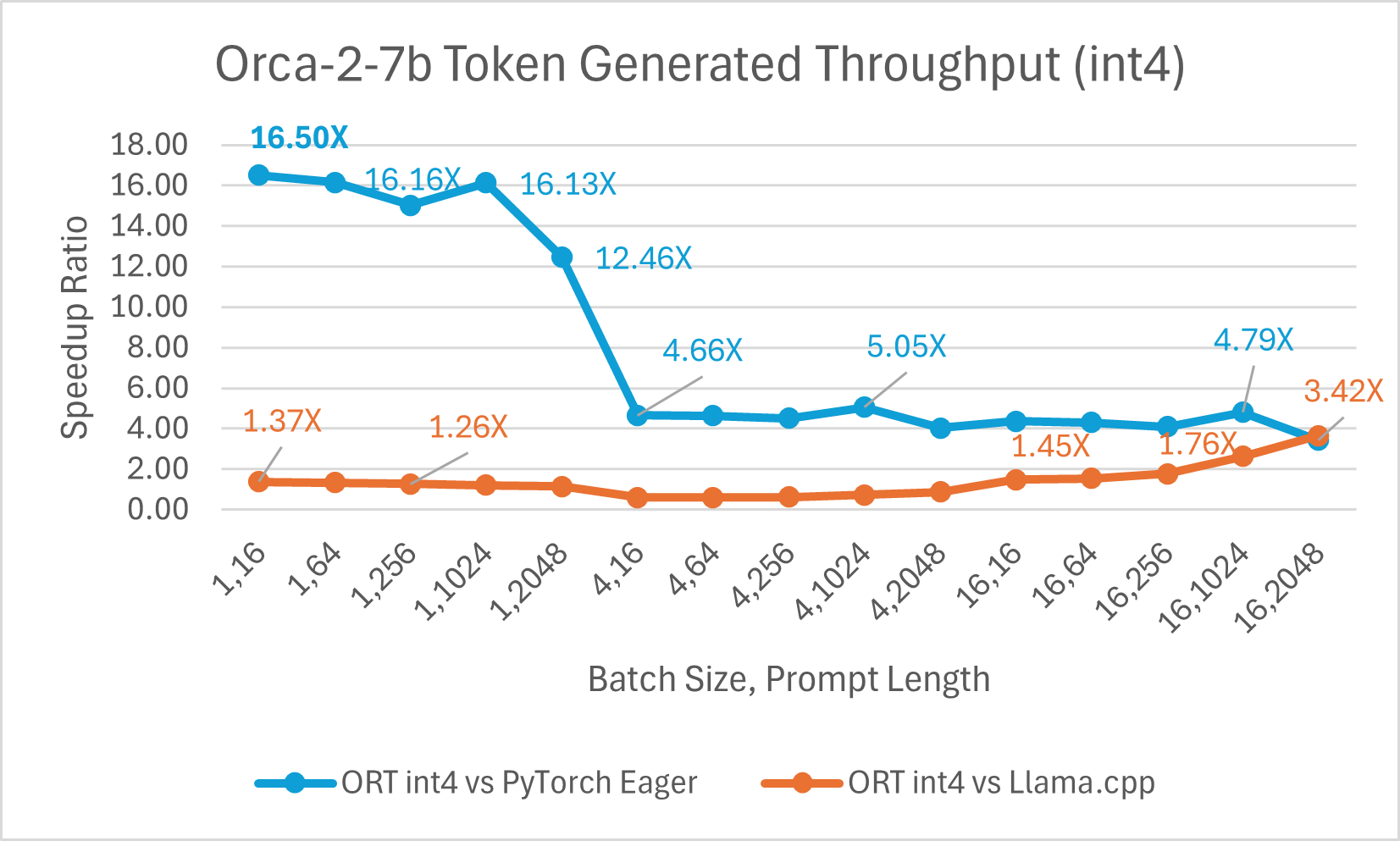
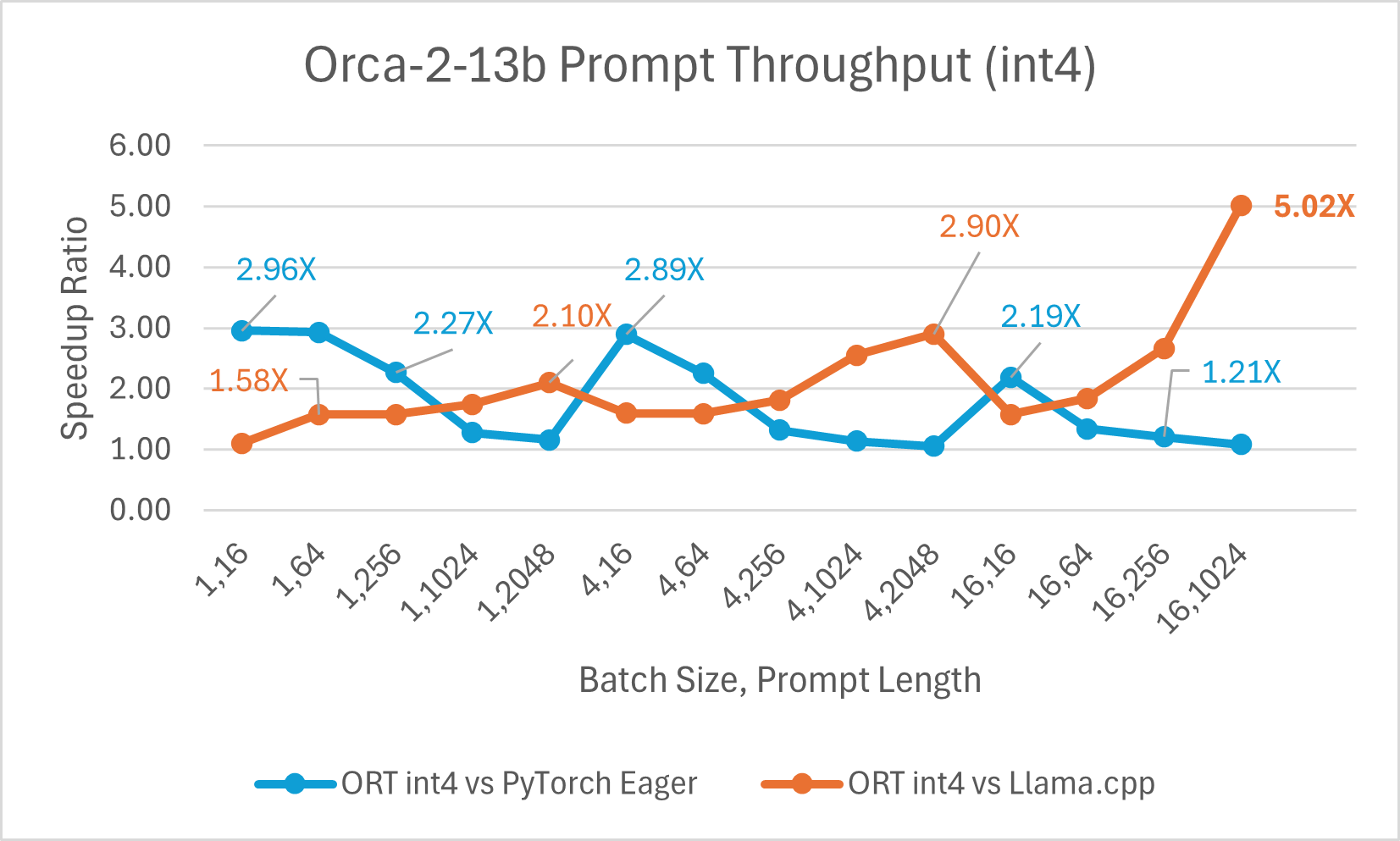
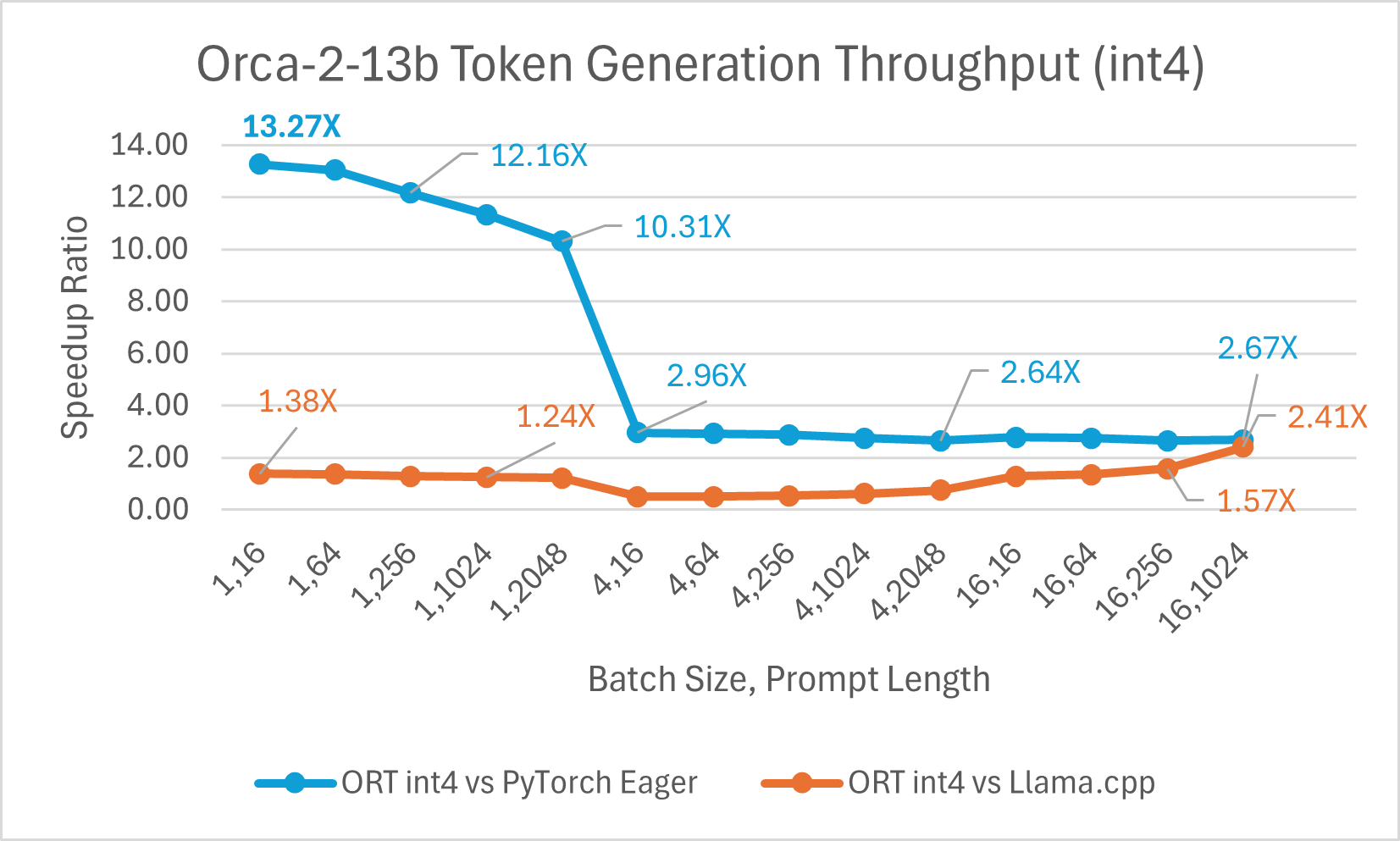
使用 ONNX Runtime float16 的 Orca-2 7b 效能比較也顯示出在提示和令牌生成吞吐量方面的顯著提升。
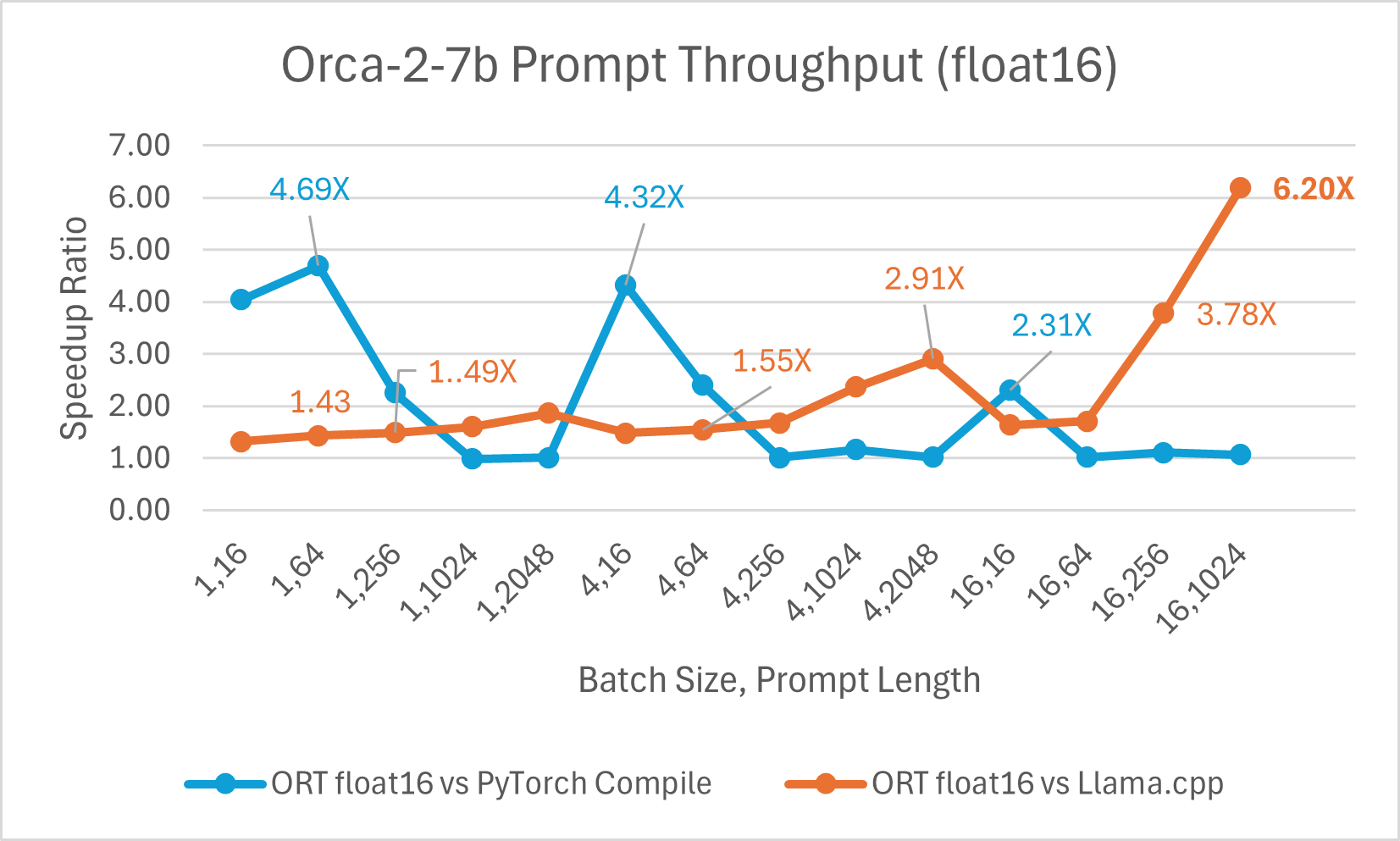
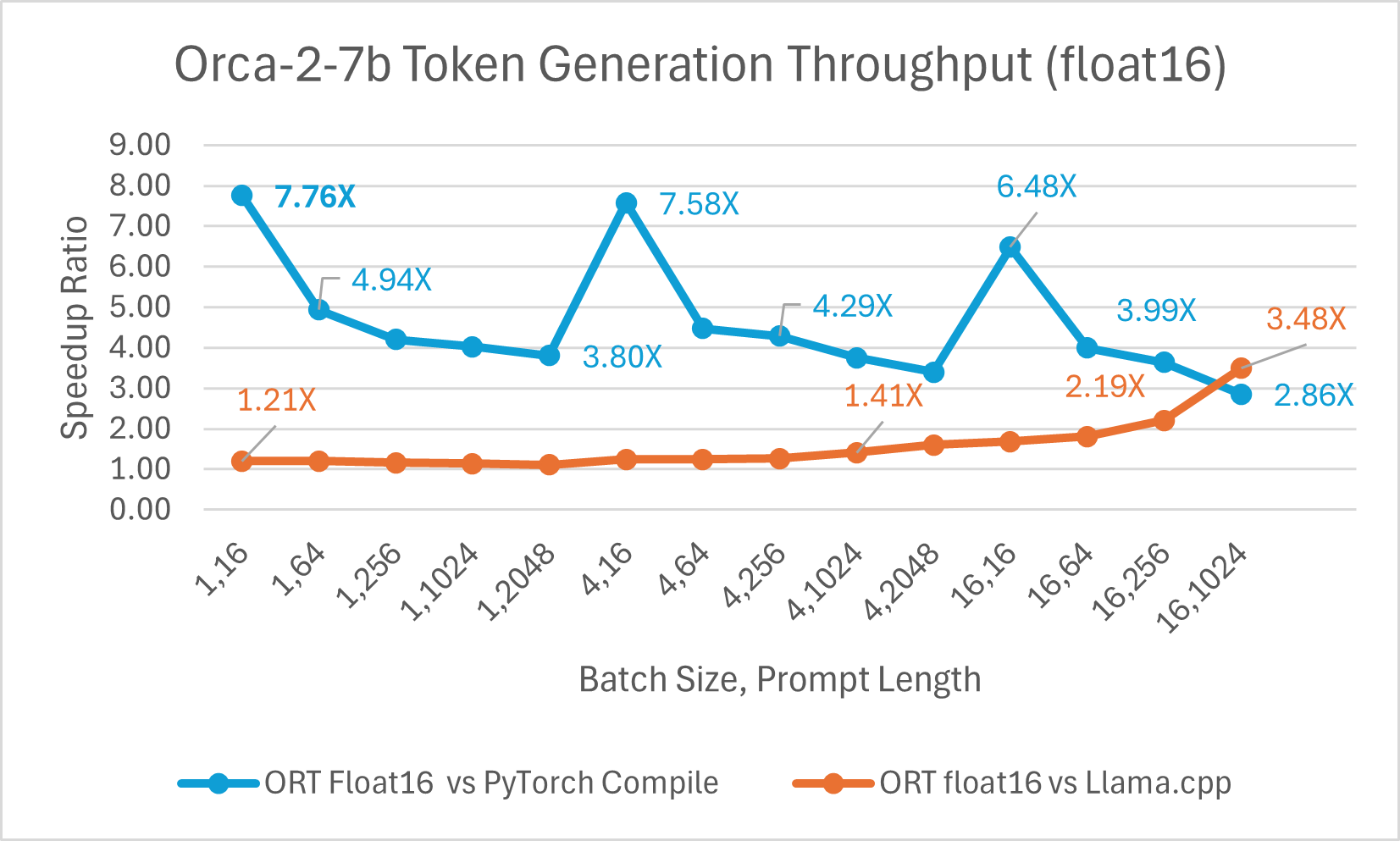
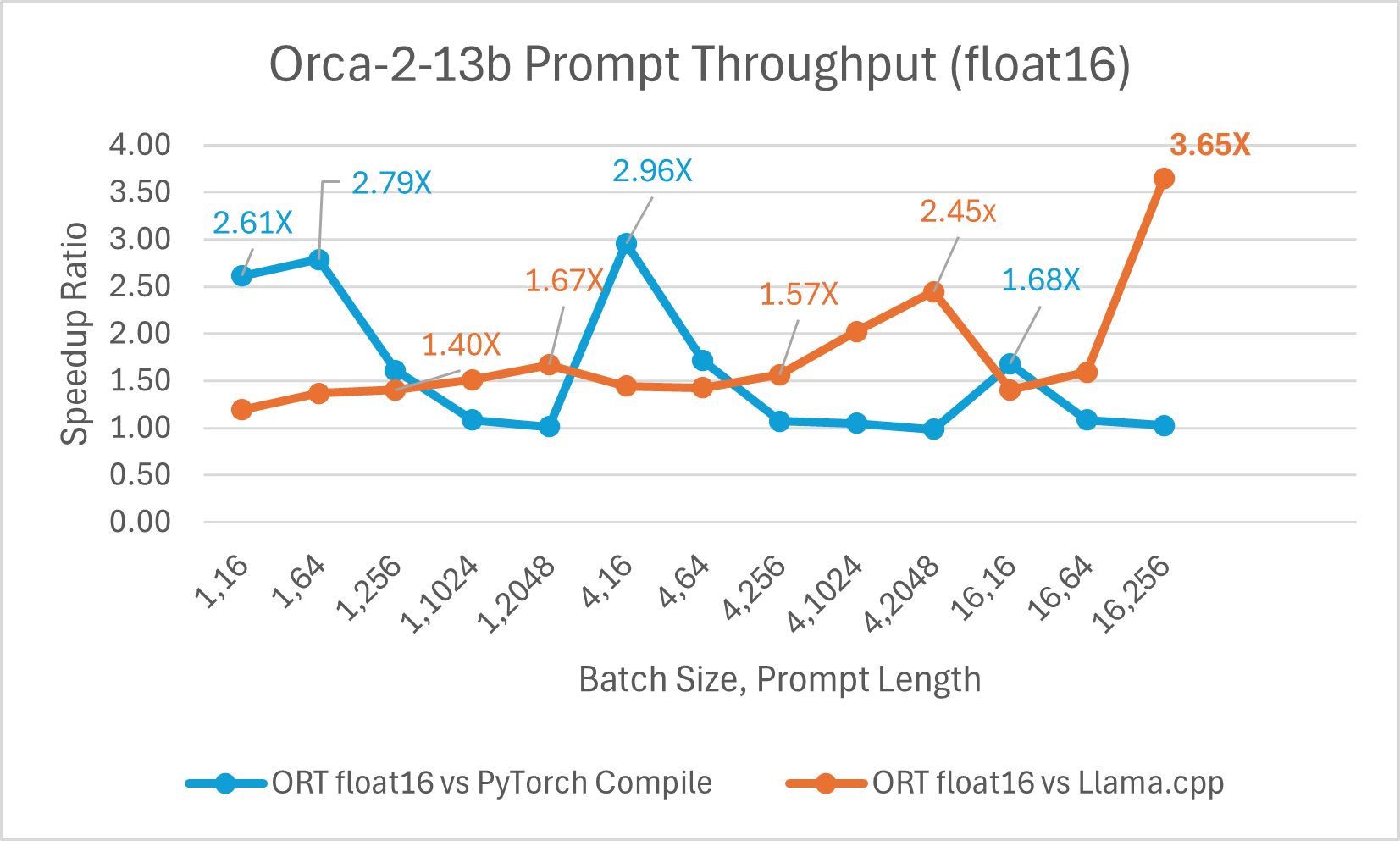
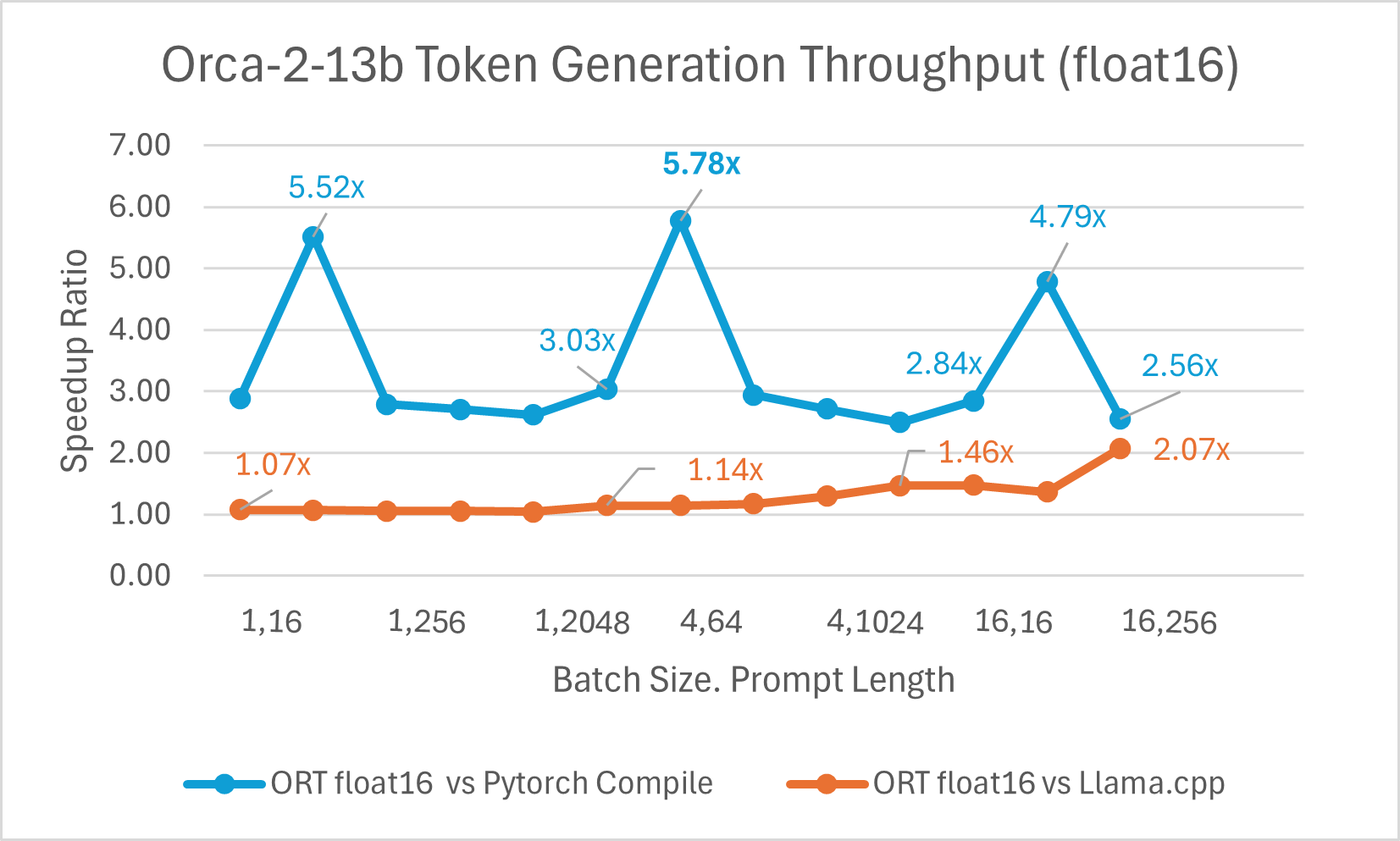
Orca-2 基準測試在 1 塊 A100 GPU 上完成,SKU: Standard_ND96amsr_A100_v4,軟體包:torch 2.2.0, triton 2.2.0, onnxruntime-gpu 1.17.0, deepspeed 0.13.2, llama.cpp - commit 594fca3fefe27b8e95cfb1656eb0e160ad15a793, transformers 4.37.2
訓練
Orca-2-7B 也受益於使用 ORT 進行訓練加速。我們使用 LoRA 並啟用稀疏性最佳化,對 Orca-2-7B 模型進行了序列長度為 512 的訓練,並觀察到良好的效能提升。以下資料是 Orca-2-7B 模型使用 DeepSpeed Stage-2 進行 5 個 epoch 訓練,批處理大小為 1,在 wikitext 資料集上的結果。
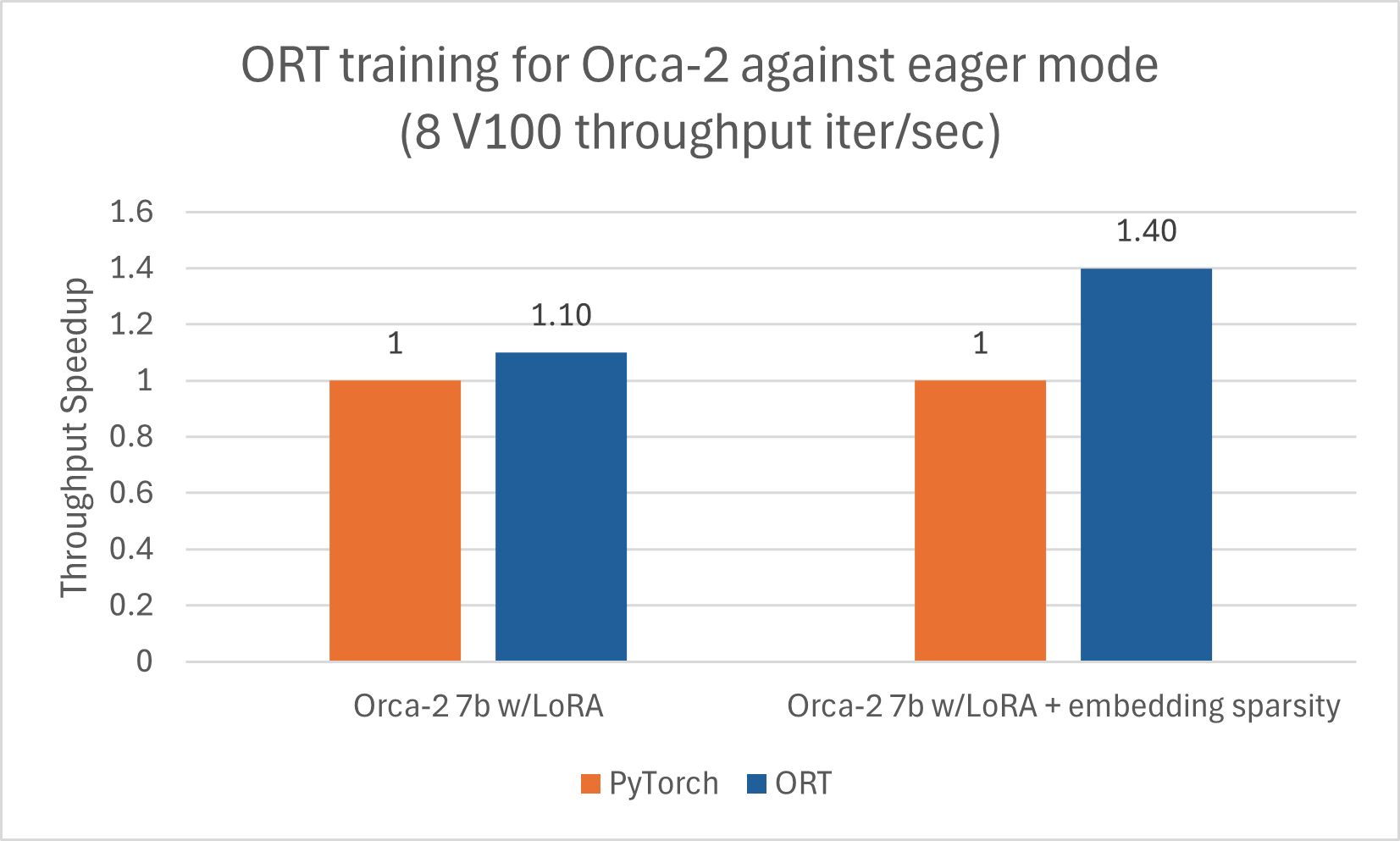 使用 ACPT 映象:nightly-ubuntu2004-cu118-py38-torch230dev:20240131
使用 ACPT 映象:nightly-ubuntu2004-cu118-py38-torch230dev:20240131 Gemma
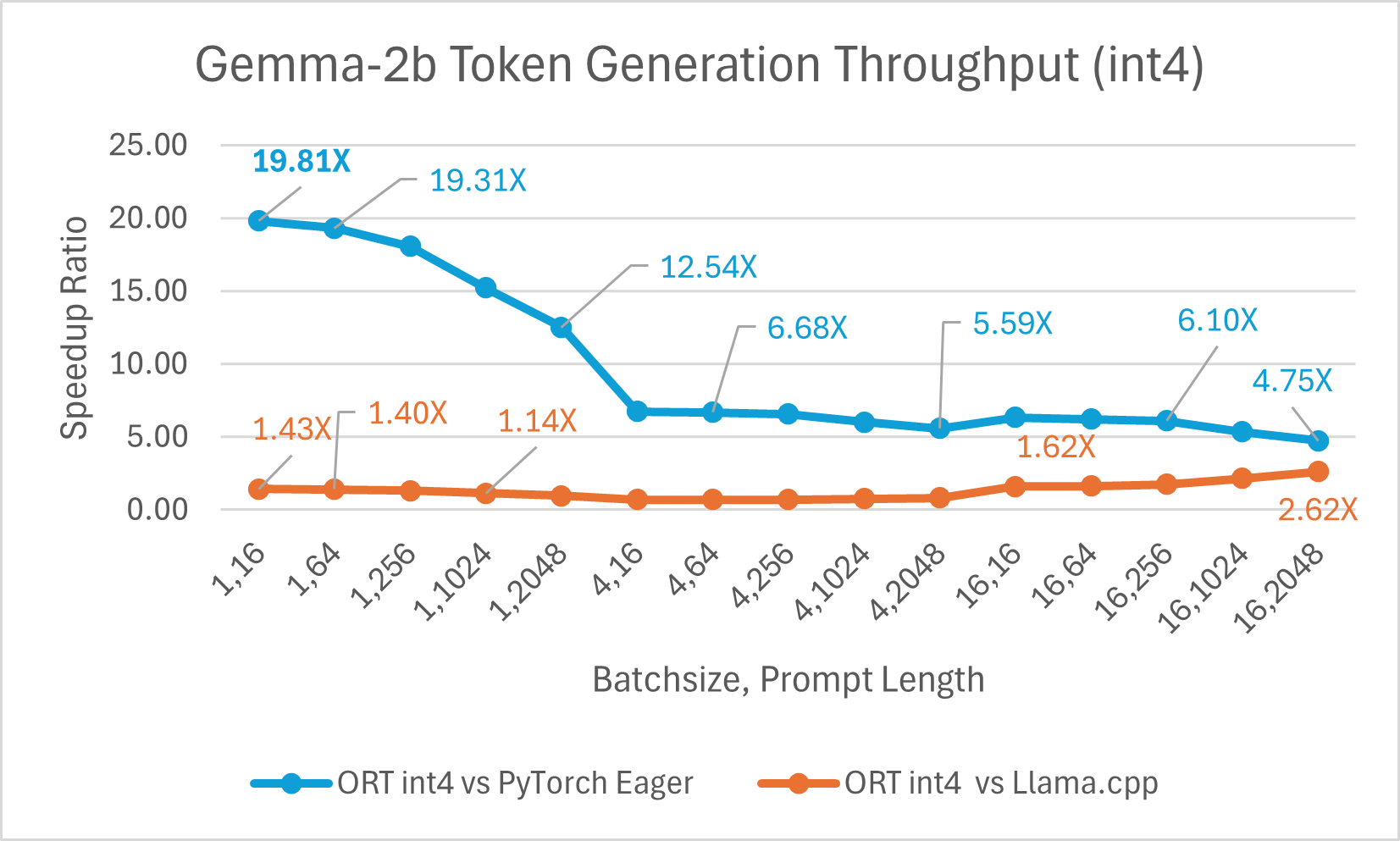
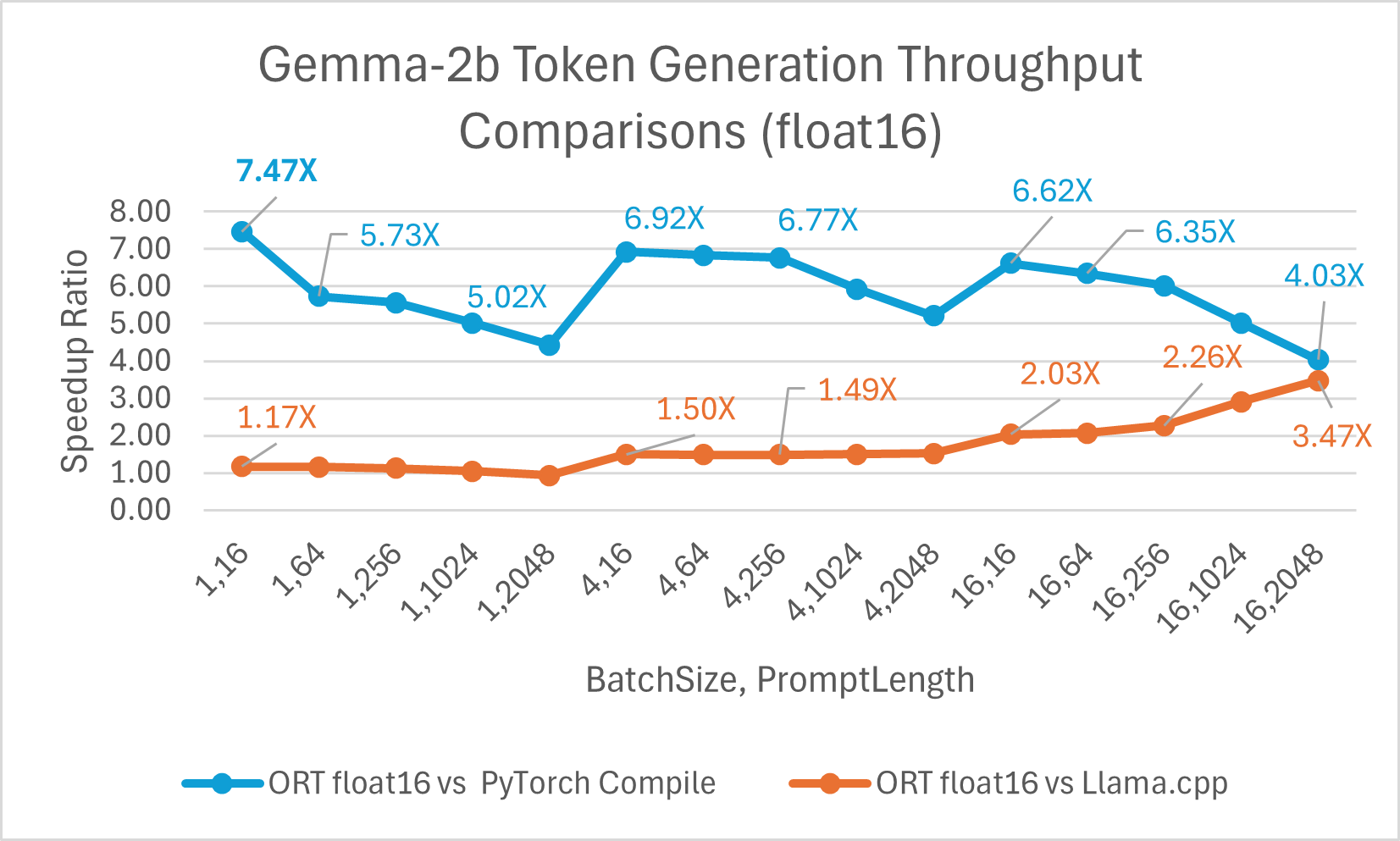
Gemma 是一個輕量級開放模型系列,由 Google 用於建立 Gemini 模型的研究和技術構建而成。它提供兩種尺寸:2B 和 7B。每種尺寸都發布了預訓練和指令微調版本。ONNX Runtime 可用於最佳化和高效執行任何開源模型。我們對 Gemma-2B 模型進行了基準測試,結果顯示使用 float16 的 ONNX Runtime 比 PyTorch Compile 快高達 7.47 倍,比 Llama.cpp 快高達 3.47 倍。使用 int4 量化的 ORT 比 PyTorch Eager 快高達 19.81 倍,比 Llama.cpp 快 2.62 倍。
總結
總之,ONNX Runtime (ORT) 為包括 Phi-2、Mistral、CodeLlama、SDXL-Turbo、Llama-2、Orca-2 和 Gemma 在內的多個模型提供了顯著的效能改進。ORT 提供最先進的融合和核心最佳化,包括對 float16 和 int4 量化的支援,從而實現更快的推理速度和更低的成本。在提示和令牌生成吞吐量方面,ORT 優於 PyTorch 和 Llama.cpp 等其他框架。ORT 在訓練大型語言模型 (LLM) 方面也顯示出顯著優勢,批處理大小越大,效能提升越明顯,並且與最先進的技術結合良好,可實現高效的大型模型訓練。