ONNX Runtime 1.17:支援 CUDA 12、Phi-2 最佳化、WebGPU 及更多精彩功能!
作者
Sophie Schoenmeyer, Parinita Rahi, Kshama Pawar, Caroline Zhu, Chad Pralle, Emma Ning, Natalie Kershaw, Jian Chen2024 年 2 月 28 日
我們最近釋出了 ONNX Runtime 1.17 版本,其中包含大量新功能,旨在進一步簡化機器學習模型的推理和訓練過程,使其在各種平臺上的執行速度比以往更快。此版本改進了我們的一些現有功能,並帶來了令人興奮的新功能,例如 Phi-2 最佳化、透過裝置端訓練在瀏覽器中訓練模型、支援 WebGPU 的 ONNX Runtime Web 等等。
有關新功能的完整列表以及各種資源,請檢視 GitHub 上的 1.17 版本 和我們最近的 1.17.1 補丁版本。
模型最佳化
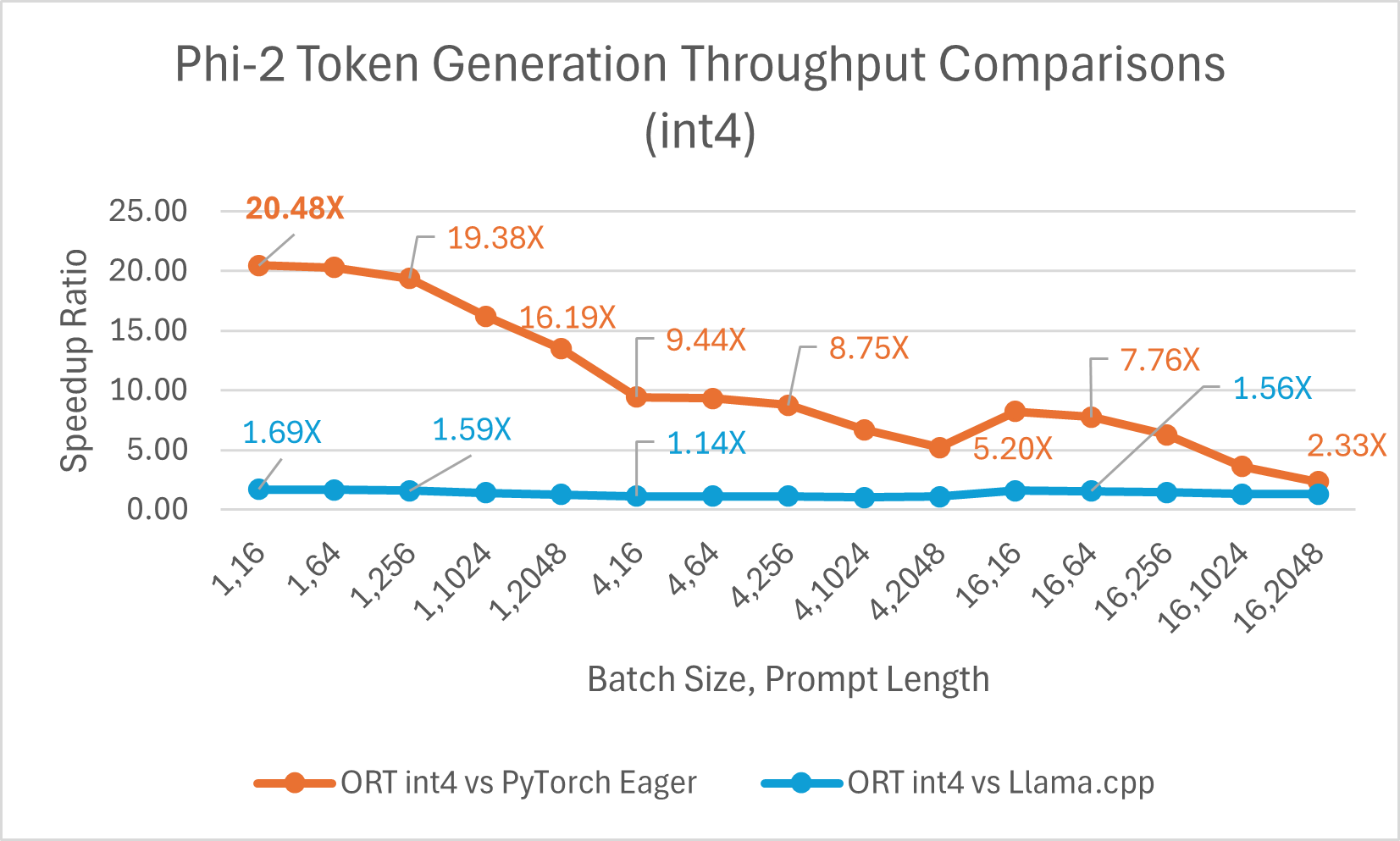
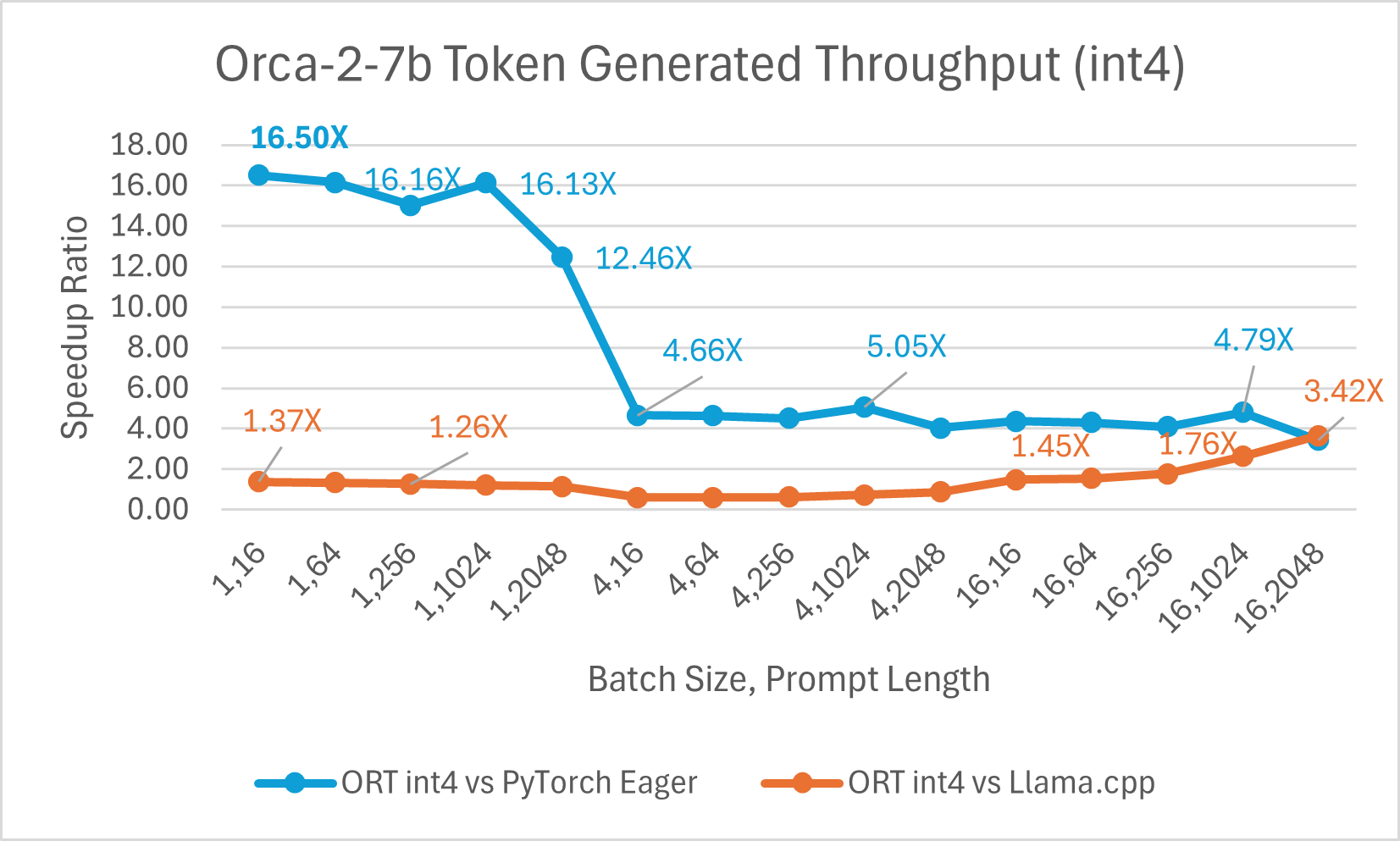
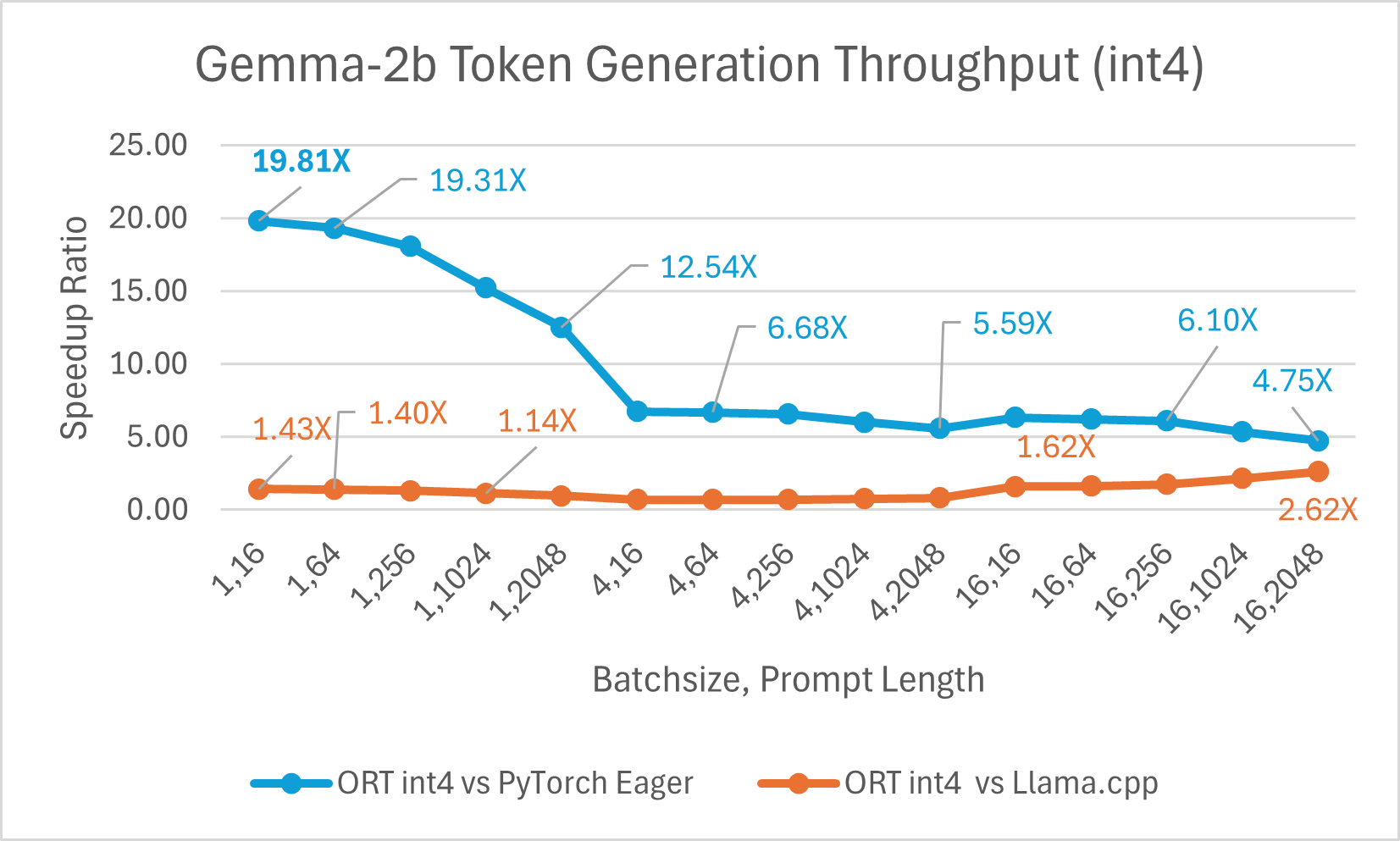
ONNX Runtime (ORT) 1.17 版本為多種模型提供了改進的推理效能,例如 Phi-2、Mistral、CodeLlama、Google 的 Gemma、SDXL-Turbo 等,這得益於採用了最先進的融合和核心最佳化,並支援 float16 和 int4 量化。此版本中新增的 ORT 最佳化包括注意力(Attention)、多頭注意力(Multi-Head Attention)、分組查詢注意力(Grouped-Query Attention)和旋轉位置嵌入(Rotary Embedding)ORT 核心改進。在提示和令牌生成吞吐量方面,ORT 優於 PyTorch、DeepSpeed 和 Llama.cpp 等其他框架,加速效果高達 20 倍。具體而言,我們觀察到 Phi-2 的效能提升高達 20.5 倍,Orca-2 高達 16.0 倍,Gemma 高達 19.8 倍(有關每個模型的更多詳細資訊,請參閱下方連結的部落格)。由於特殊的 GemV 核心實現,採用 int4 量化的 ONNX Runtime 在批處理大小為 1 時表現最佳。總體而言,ONNX Runtime 在多種批處理大小和提示長度下都表現出顯著的效能提升。
ONNX Runtime 在訓練大型語言模型(LLM)方面也顯示出顯著優勢,這些優勢通常會隨著批處理大小的增加而增大。例如,在 2 塊 A100 GPU 上,對於使用 LoRA 的 Phi-2 模型,ORT 比 PyTorch Eager 模式快 1.2 倍,比 torch.compile 快 1.5 倍。ORT 對於其他大型語言模型(如 Llama、Mistral 和 Orca-2)結合 LoRA 或 QLoRA 也顯示出優勢。
要了解更多關於如何使用 ONNX Runtime 1.17 提高生成式 AI 模型效能的資訊,請檢視我們最近在 ONNX Runtime 部落格上釋出的文章:使用 ONNX Runtime 加速 Phi-2、CodeLlama、Gemma 及其他生成式 AI 模型。

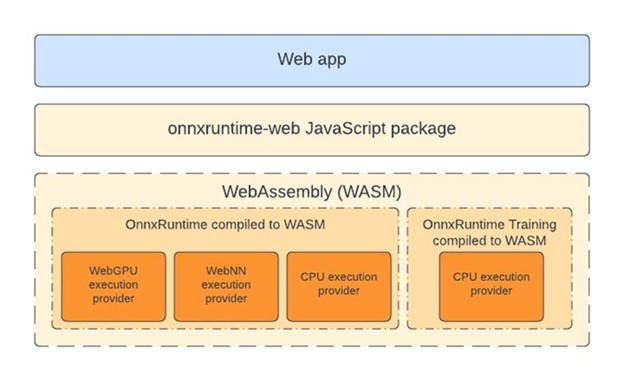
瀏覽器內訓練
裝置端訓練允許您使用裝置資料來改善開發人員應用程式的使用者體驗。它支援聯邦學習等場景,即使用裝置上的資料訓練全域性模型。透過 1.17 版本,ORT 現在將支援在瀏覽器中使用裝置端訓練來訓練機器學習模型。
要了解更多關於如何透過裝置端訓練在瀏覽器中訓練模型的資訊,請檢視微軟開源部落格上的這篇最新文章:裝置端訓練:在瀏覽器中訓練模型。
DirectML NPU 支援
隨著 DirectML 1.13.1 和 ONNX Runtime 1.17 的釋出,DirectML(Windows 機器學習平臺 API)現已提供神經網路處理器(NPU)加速的開發者預覽支援。此開發者預覽版本支援在配備英特爾® 酷睿™ Ultra 處理器和英特爾® AI 加速技術的新款 Windows 11 裝置上執行部分模型。
要了解更多關於 DirectML 中 NPU 支援的資訊,請檢視 Windows 開發者部落格上的這篇最新文章:DirectML 中引入神經網路處理器(NPU)支援(開發者預覽版)。
ONNX Runtime Web 與 WebGPU
WebGPU 使 Web 開發者能夠利用 GPU 硬體進行高效能計算。ONNX Runtime 1.17 版本正式推出了 ONNX Runtime Web 中的 WebGPU 執行提供程式,這使得複雜的模型能夠在瀏覽器中完全高效地執行(檢視 WebGPU 瀏覽器相容性列表)。這項進步透過 SD-Turbo 等模型的有效執行得到了證明,為基於 CPU 的瀏覽器內機器學習難以達到效能標準的場景開闢了新的可能性。
要了解更多關於 ONNX Runtime Web 如何透過 WebGPU 進一步加速瀏覽器內機器學習的資訊,請檢視我們最近在微軟開源部落格上釋出的文章:ONNX Runtime Web 利用 WebGPU 在瀏覽器中釋放生成式 AI 的力量。
ONNX Runtime Mobile 中的 YOLOv8 姿態估計場景
此版本新增了對執行 YOLOv8 模型進行姿態估計的支援。姿態估計涉及處理影像中檢測到的物件,並識別影像中人物的位置和方向。核心 YOLOv8 模型返回一組關鍵點,代表被檢測人物身體的特定部位,例如關節和其他顯著特徵。將預處理和後處理包含在 ONNX 模型中,使得開發人員可以直接提供輸入影像(可以是常見影像格式或原始 RGB 值),並輸出帶有邊界框和關鍵點的影像。
要了解更多關於如何在移動裝置上構建和執行包含內建預處理和後處理的 ONNX 模型以進行物件檢測和姿態估計的資訊,請檢視 ONNX Runtime 文件中我們最近的教程:使用 YOLOv8 進行物件檢測和姿態估計。

CUDA 12 軟體包
作為 1.17 版本的一部分,ONNX Runtime 現在透過引入適用於 Python 和 NuGet 的 CUDA 12 軟體包,確保了與 Nvidia CUDA 執行提供程式的多個版本相容。透過這種更靈活的方法,使用者現在可以同時使用 CUDA 11 和 CUDA 12,從而更無縫地整合尖端硬體加速技術。
要為 ONNX Runtime GPU 安裝 CUDA 12,請參閱 ONNX Runtime 文件中的說明:安裝 ONNX Runtime GPU (CUDA 12.X)。