QNN 執行提供者
ONNX Runtime 的 QNN 執行提供者支援在高通晶片組上進行硬體加速執行。它使用高通 AI 引擎直接 SDK (QNN SDK) 從 ONNX 模型構建 QNN 圖,該圖可由受支援的加速器後端庫執行。OnnxRuntime QNN 執行提供者可用於配備高通驍龍 SOC 的 Android 和 Windows 裝置。
目錄
- 安裝先決條件(僅限從原始碼構建)
- 構建(Android 和 Windows)
- 預構建包(僅限 Windows)
- Qualcomm AI Hub
- 配置選項
- 支援的 ONNX 運算子
- 使用 QNN EP 的 HTP 後端執行模型 (Python)
- QNN 上下文二進位制快取功能
- QNN EP 權重共享
- 使用方法
- 錯誤處理
- 在 QNN EP 中新增新運算子支援
- 混合精度支援
- LoRAv2 支援
安裝先決條件(僅限從原始碼構建)
如果您從原始碼構建 QNN 執行提供者,您應該首先從 https://qpm.qualcomm.com/#/main/tools/details/Qualcomm_AI_Runtime_SDK 下載高通 AI 引擎直接 SDK (QNN SDK)。
QNN 版本要求
ONNX Runtime QNN 執行提供者已使用 QNN 2.22.x 和高通 SC8280、SM8350、驍龍 X SOC 在 Android 和 Windows 上構建並測試。
構建(Android 和 Windows)
有關構建說明,請參閱構建頁面。
預構建包(僅限 Windows)
注意:從 1.18.0 版本開始,您無需單獨下載和安裝 QNN SDK。所需的 QNN 依賴庫已包含在 OnnxRuntime 包中。
- NuGet package
- Microsoft.ML.OnnxRuntime.QNN 每夜構建包的源可在此處找到
- Python 包
- 要求
- Windows ARM64(用於在高通 NPU 的本地裝置上進行推理)
- Windows X64(用於模型量化。請參閱生成量化模型)
- Python 3.11.x
- Numpy 1.25.2 或 >= 1.26.4
- 安裝:
pip install onnxruntime-qnn - 安裝每夜構建包
python -m pip install --pre --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/ORT-Nightly/pypi/simple onnxruntime-qnn
- 要求
Qualcomm AI Hub
Qualcomm AI Hub 可用於在高通託管裝置上最佳化和執行模型。OnnxRuntime QNN 執行提供者是 Qualcomm AI Hub 中支援的執行時。
配置選項
QNN 執行提供者支援多種配置選項。這些提供者選項以鍵值字串對的形式指定。
EP 提供者選項
"backend_type" | 描述 |
|---|---|
| ‘cpu’ | 啟用 CPU 後端。對整合測試很有用。CPU 後端是 QNN 運算子的參考實現。 |
| ‘gpu’ | 啟用 GPU 後端。 |
| ‘htp’ | 啟用 HTP 後端。將計算解除安裝到 NPU。預設值。 |
| ‘saver’ | 啟用 Saver 後端。 |
"backend_path" | 描述 |
|---|---|
| ‘libQnnCpu.so’ 或 ‘QnnCpu.dll’ | 啟用 CPU 後端。請參閱 backend_type ‘cpu’。 |
| ‘libQnnHtp.so’ 或 ‘QnnHtp.dll’ | 啟用 HTP 後端。請參閱 backend_type ‘htp’。 |
注意: backend_path 是 backend_type 的替代方案。兩者中最多隻能指定一個。backend_path 需要平臺特定的路徑(例如,libQnnCpu.so 與 QnnCpu.dll),但也允許指定任意路徑。
"profiling_level" | 描述 |
|---|---|
| ‘off’ | 預設值。 |
| ‘basic’ | |
| ‘detailed’ |
"profiling_file_path" | 描述 |
|---|---|
| ‘your_qnn_profile_path.csv’ | 指定用於轉儲 QNN 效能分析事件的 csv 檔案路徑 |
有關效能分析的更多資訊,請參閱效能分析工具
除了在編譯時設定 profiling_level 外,還可以透過 ETW (Windows) 動態啟用效能分析。有關詳細資訊,請參閱跟蹤
"rpc_control_latency" | 描述 |
|---|---|
| 微秒(字串) | 允許客戶端以微秒為單位設定 RPC 控制延遲 |
"vtcm_mb" | 描述 |
|---|---|
| 大小(MB)(字串) | QNN VTCM 大小(MB),預設為 0(未設定) |
"htp_performance_mode" | 描述 |
|---|---|
| ‘burst’ | |
| ‘balanced’ | |
| ‘default’ | 預設值。 |
| ‘high_performance’ | |
| ‘high_power_saver’ | |
| ‘low_balanced’ | |
| ‘low_power_saver’ | |
| ‘power_saver’ | |
| ‘sustained_high_performance’ |
"qnn_saver_path" | 描述 |
|---|---|
| ‘QnnSaver.dll’ 或 ‘libQnnSaver.so’ 的檔案路徑 | QNN Saver 後端庫的檔案路徑。將 QNN API 呼叫轉儲到磁碟以供重放/除錯。 |
"qnn_context_priority" | 描述 |
|---|---|
| ‘low’ | |
| ‘normal’ | 預設值。 |
| ‘normal_high’ | |
| ‘high’ |
"htp_graph_finalization_optimization_mode" | 描述 |
|---|---|
| ‘0’ | 預設值。 |
| ‘1’ | 更快的準備時間,但圖最佳化程度較低。 |
| ‘2’ | 更長的準備時間,但圖最佳化程度更高。 |
| ‘3’ | 最長的準備時間,最有可能生成更最佳化的圖。 |
"soc_model" | 描述 |
|---|---|
| 型號(字串) | SoC 型號。有關有效值,請參閱 QNN SDK 文件。預設為“0”(未知)。 |
"htp_arch" | 描述 |
|---|---|
| 硬體架構 | HTP 架構編號。有關有效值,請參閱 QNN SDK 文件。預設(無) |
"device_id" | 描述 |
|---|---|
| 裝置 ID(字串) | 設定 htp_arch 時要使用的裝置 ID。預設為“0”(對於單個裝置)。 |
"enable_htp_fp16_precision" | 描述 示例 |
|---|---|
| ‘0’ | 停用。如果是 fp32 模型,則使用 fp32 精度進行推理。 |
| ‘1’ | 預設。啟用 float32 模型以使用 fp16 精度進行推理。 |
"offload_graph_io_quantization" | 描述 |
|---|---|
| ‘0’ | 停用。QNN EP 將處理圖 I/O 的量化和反量化。 |
| ‘1’ | 預設。啟用。將圖 I/O 的量化和反量化解除安裝到 CPU EP。 |
"enable_htp_shared_memory_allocator" | 描述 |
|---|---|
| ‘0’ | 預設。停用。 |
| ‘1’ | 啟用 QNN HTP 共享記憶體分配器。需要 libcdsprpc.so/dll 可用。程式碼示例 |
執行選項
"qnn.lora_config" | 描述 |
|---|---|
| 配置檔案路徑 | LoRAv2 配置檔案路徑。配置的格式將在 LoRAv2 支援中提及。 |
支援的 ONNX 運算子
| 運算子 | 備註 |
|---|---|
| ai.onnx:Abs | |
| ai.onnx:Add | |
| ai.onnx:And | |
| ai.onnx:ArgMax | |
| ai.onnx:ArgMin | |
| ai.onnx:Asin | |
| ai.onnx:Atan | |
| ai.onnx:AveragePool | |
| ai.onnx:BatchNormalization | 自 1.18.0 起支援 fp16 |
| ai.onnx:Cast | |
| ai.onnx:Clip | 自 1.18.0 起支援 fp16 |
| ai.onnx:Concat | |
| ai.onnx:Conv | 自 1.18.0 起支援 3D |
| ai.onnx:ConvTranspose | 自 1.18.0 起支援 3D |
| ai.onnx:Cos | |
| ai.onnx:DepthToSpace | |
| ai.onnx:DequantizeLinear | |
| ai.onnx:Div | |
| ai.onnx:Elu | |
| ai.onnx:Equal | |
| ai.onnx:Exp | |
| ai.onnx:Expand | |
| ai.onnx:Flatten | |
| ai.onnx:Floor | |
| ai.onnx:Gather | 僅支援正索引 |
| ai.onnx:Gelu | |
| ai.onnx:Gemm | |
| ai.onnx:GlobalAveragePool | |
| ai.onnx:Greater | |
| ai.onnx:GreaterOrEqual | |
| ai.onnx:GridSample | |
| ai.onnx:HardSwish | |
| ai.onnx:InstanceNormalization | |
| ai.onnx:LRN | |
| ai.onnx:LayerNormalization | |
| ai.onnx:LeakyRelu | |
| ai.onnx:Less | |
| ai.onnx:LessOrEqual | |
| ai.onnx:Log | |
| ai.onnx:LogSoftmax | |
| ai.onnx:LpNormalization | p == 2 |
| ai.onnx:MatMul | HTP 後端支援的輸入資料型別:(uint8, uint8), (uint8, uint16), (uint16, uint8) |
| ai.onnx:Max | |
| ai.onnx:MaxPool | |
| ai.onnx:Min | |
| ai.onnx:Mul | |
| ai.onnx:Neg | |
| ai.onnx:Not | |
| ai.onnx:Or | |
| ai.onnx:Prelu | 自 1.18.0 起支援 fp16, int32 |
| ai.onnx:Pad | |
| ai.onnx:Pow | |
| ai.onnx:QuantizeLinear | |
| ai.onnx:ReduceMax | |
| ai.onnx:ReduceMean | |
| ai.onnx:ReduceMin | |
| ai.onnx:ReduceProd | |
| ai.onnx:ReduceSum | |
| ai.onnx:Relu | |
| ai.onnx:Resize | |
| ai.onnx:Round | |
| ai.onnx:Sigmoid | |
| ai.onnx:Sign | |
| ai.onnx:Sin | |
| ai.onnx:Slice | |
| ai.onnx:Softmax | |
| ai.onnx:SpaceToDepth | |
| ai.onnx:Split | |
| ai.onnx:Sqrt | |
| ai.onnx:Squeeze | |
| ai.onnx:Sub | |
| ai.onnx:Tanh | |
| ai.onnx:Tile | |
| ai.onnx:TopK | |
| ai.onnx:Transpose | |
| ai.onnx:Unsqueeze | |
| ai.onnx:Where | |
| com.microsoft:DequantizeLinear | 提供 16 位整數反量化支援 |
| com.microsoft:Gelu | |
| com.microsoft:QuantizeLinear | 提供 16 位整數量化支援 |
支援的資料型別因運算子和 QNN 後端而異。有關更多資訊,請參閱 QNN SDK 文件。
使用 QNN EP 的 HTP 後端執行模型 (Python)
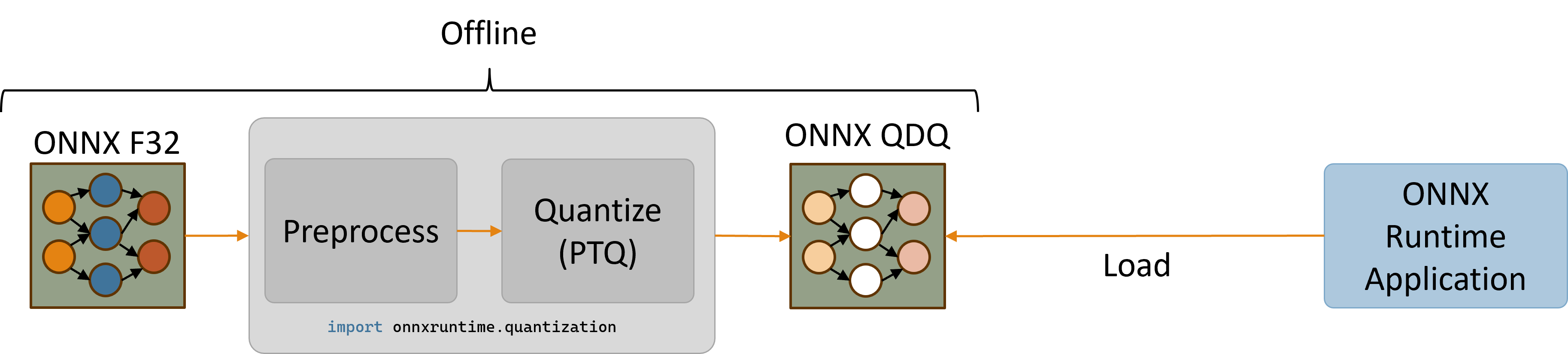
QNN HTP 後端僅支援量化模型。具有 32 位浮點啟用和權重的模型必須首先進行量化以使用較低的整數精度(例如,8 位或 16 位整數)。
本節提供了量化模型以及隨後使用 Python API 在 QNN EP 的 HTP 後端上執行量化模型的說明。有關量化概念的更廣泛概述,請參閱量化頁面。
模型要求
QNN EP 不支援具有動態形狀的模型(例如,動態批處理大小)。動態形狀必須固定到特定值。有關更多資訊,請參閱固定動態輸入形狀的文件。
此外,QNN EP 支援 ONNX 運算子的子集(例如,不支援迴圈和條件語句)。請參閱支援的 ONNX 運算子列表。
生成量化模型(僅限 x64)
ONNX Runtime Python 包透過 onnxruntime.quantization 匯入提供了量化 ONNX 模型的實用程式。由於在 ARM64 上安裝 onnx 包存在問題,量化實用程式目前僅在 x86_64 上受支援。因此,建議要麼使用 x64 機器量化模型,要麼在 Windows ARM64 機器上使用單獨的 x64 Python 安裝。
安裝 ONNX Runtime x64 Python 包。(請注意,您必須使用 x64 包進行模型量化。使用 arm64 包進行推理和利用 HTP/NPU)
python -m pip install onnxruntime-qnn
QNN EP 的量化需要使用校準輸入資料。使用能代表典型模型輸入的校準資料集對於生成準確的量化模型至關重要。
以下程式碼片段定義了一個示例 DataReader 類,用於生成隨機 float32 輸入資料。請注意,使用隨機輸入資料很可能會生成不準確的量化模型。有關如何建立從磁碟影像檔案提供輸入的 CalibrationDataReader 的一個示例,請參閱 Resnet 資料讀取器的實現。
# data_reader.py
import numpy as np
import onnxruntime
from onnxruntime.quantization import CalibrationDataReader
class DataReader(CalibrationDataReader):
def __init__(self, model_path: str):
self.enum_data = None
# Use inference session to get input shape.
session = onnxruntime.InferenceSession(model_path, providers=['CPUExecutionProvider'])
inputs = session.get_inputs()
self.data_list = []
# Generate 10 random float32 inputs
# TODO: Load valid calibration input data for your model
for _ in range(10):
input_data = {inp.name : np.random.random(inp.shape).astype(np.float32) for inp in inputs}
self.data_list.append(input_data)
self.datasize = len(self.data_list)
def get_next(self):
if self.enum_data is None:
self.enum_data = iter(
self.data_list
)
return next(self.enum_data, None)
def rewind(self):
self.enum_data = None
以下程式碼片段預處理原始模型,然後將預處理後的模型量化為使用 uint16 啟用和 uint8 權重。儘管量化實用程式公開了 uint8、int8、uint16 和 int16 量化資料型別,但 QNN 運算子通常支援 uint8 和 uint16 資料型別。有關每個 QNN 運算子的資料型別要求,請參閱 QNN SDK 運算子文件。
# quantize_model.py
import data_reader
import numpy as np
import onnx
from onnxruntime.quantization import QuantType, quantize
from onnxruntime.quantization.execution_providers.qnn import get_qnn_qdq_config, qnn_preprocess_model
if __name__ == "__main__":
input_model_path = "model.onnx" # TODO: Replace with your actual model
output_model_path = "model.qdq.onnx" # Name of final quantized model
my_data_reader = data_reader.DataReader(input_model_path)
# Pre-process the original float32 model.
preproc_model_path = "model.preproc.onnx"
model_changed = qnn_preprocess_model(input_model_path, preproc_model_path)
model_to_quantize = preproc_model_path if model_changed else input_model_path
# Generate a suitable quantization configuration for this model.
# Note that we're choosing to use uint16 activations and uint8 weights.
qnn_config = get_qnn_qdq_config(model_to_quantize,
my_data_reader,
activation_type=QuantType.QUInt16, # uint16 activations
weight_type=QuantType.QUInt8) # uint8 weights
# Quantize the model.
quantize(model_to_quantize, output_model_path, qnn_config)
執行 python quantize_model.py 將生成一個名為 model.qdq.onnx 的量化模型,該模型可以透過 ONNX Runtime 的 QNN EP 在 Windows ARM64 裝置上執行。
有關量化實用程式用法的更多資訊,請參閱以下頁面
- CPU EP 上 mobilenet 的量化示例
- quantization/execution_providers/qnn/preprocess.py
- quantization/execution_providers/qnn/quant_config.py
在 Windows ARM64 上執行量化模型 (onnxruntime-qnn 版本 >= 1.18.0)
安裝適用於 QNN EP 的 ONNX Runtime ARM64 Python 包(需要 Python 3.11.x 和 Numpy 1.25.2 或 >= 1.26.4)
python -m pip install onnxruntime-qnn
以下 Python 程式碼片段建立了一個帶有 QNN EP 的 ONNX Runtime 會話,並在 HTP 後端上執行量化模型 model.qdq.onnx。
# run_qdq_model.py
import onnxruntime
import numpy as np
options = onnxruntime.SessionOptions()
# (Optional) Enable configuration that raises an exception if the model can't be
# run entirely on the QNN HTP backend.
options.add_session_config_entry("session.disable_cpu_ep_fallback", "1")
# Create an ONNX Runtime session.
# TODO: Provide the path to your ONNX model
session = onnxruntime.InferenceSession("model.qdq.onnx",
sess_options=options,
providers=["QNNExecutionProvider"],
provider_options=[{"backend_path": "QnnHtp.dll"}]) # Provide path to Htp dll in QNN SDK
# Run the model with your input.
# TODO: Use numpy to load your actual input from a file or generate random input.
input0 = np.ones((1,3,224,224), dtype=np.float32)
result = session.run(None, {"input": input0})
# Print output.
print(result)
執行 python run_qdq_model.py 將在 QNN HTP 後端上執行量化的 model.qdq.onnx 模型。
請注意,會話已選擇性配置為在整個模型無法在 QNN HTP 後端上執行時引發異常。這對於驗證量化模型是否完全受 QNN EP 支援非常有用。可用的會話配置包括
- session.disable_cpu_ep_fallback: 停用將不受支援的運算子回退到 CPU EP。
- ep.context_enable: 啟用 QNN 上下文快取功能以轉儲模型的快取版本,從而縮短會話建立時間。
上述程式碼片段僅指定了 backend_path 提供者選項。有關所有可用 QNN EP 提供者選項的列表,請參閱配置選項部分。
QNN 上下文二進位制快取功能
QNN 上下文在模型轉換、編譯和最終確定後包含 QNN 圖。QNN 可以將上下文序列化為二進位制檔案,這樣使用者就可以直接使用它進行後續推理(無需 QDQ 模型),從而降低模型載入成本。QNN 執行提供者支援多種會話選項來配置此功能。
轉儲 QNN 上下文二進位制檔案
- 建立會話選項,將“ep.context_enable”設定為“1”以啟用 QNN 上下文轉儲。鍵“ep.context_enable”在 onnxruntime_session_options_config_keys.h 中定義為 kOrtSessionOptionEpContextEnable。
- 使用第 1 步中建立的會話選項建立帶有 QDQ 模型的會話,並使用 HTP 後端。一旦會話建立/初始化,將建立一個帶有 QNN 上下文二進位制檔案的 Onnx 模型。無需執行會話。QNN 上下文二進位制檔案的生成可以在具有 HTP 的高通裝置上使用 Arm64 構建完成。也可以在 x64 機器上使用 x64 構建完成(由於沒有 HTP 裝置,無法執行)。
生成的帶有 QNN 上下文二進位制檔案的 Onnx 模型可以部署到生產/實際裝置以執行推理。該 Onnx 模型被 QNN 執行提供者視為普通模型。推理程式碼與在 HTP 後端上使用 QDQ 模型進行推理的程式碼保持相同。
#include "onnxruntime_session_options_config_keys.h"
// C++
Ort::SessionOptions so;
so.AddConfigEntry(kOrtSessionOptionEpContextEnable, "1");
// C
const OrtApi* g_ort = OrtGetApiBase()->GetApi(ORT_API_VERSION);
OrtSessionOptions* session_options;
CheckStatus(g_ort, g_ort->CreateSessionOptions(&session_options));
g_ort->AddSessionConfigEntry(session_options, kOrtSessionOptionEpContextEnable, "1");
# Python
import onnxruntime
options = onnxruntime.SessionOptions()
options.add_session_config_entry("ep.context_enable", "1")
配置上下文二進位制檔案路徑
如果使用者未指定路徑,生成的帶有 QNN 上下文二進位制檔案的 Onnx 模型預設名為 [input_QDQ_model_name]_ctx.onnx。使用者可以使用鍵“ep.context_file_path”在會話選項中設定路徑。以下是程式碼示例
// C++
so.AddConfigEntry(kOrtSessionOptionEpContextFilePath, "./model_a_ctx.onnx");
// C
g_ort->AddSessionConfigEntry(session_options, kOrtSessionOptionEpContextFilePath, "./model_a_ctx.onnx");
# Python
options.add_session_config_entry("ep.context_file_path", "./model_a_ctx.onnx")
啟用嵌入模式
QNN 上下文二進位制內容預設不嵌入到生成的 Onnx 模型中。將單獨生成一個 bin 檔案。檔名為 [input_model_file_name]QNN[hash_id].bin。該名稱由 Ort 提供並在生成的 Onnx 模型中跟蹤。如果對 bin 檔案進行任何更改,將導致問題。此 bin 檔案需要與生成的 Onnx 檔案放在一起。使用者可以透過將“ep.context_embed_mode”設定為“1”來啟用此功能。在這種情況下,上下文二進位制內容將嵌入到 Onnx 模型內部。
// C++
so.AddConfigEntry(kOrtSessionOptionEpContextEmbedMode, "1");
// C
g_ort->AddSessionConfigEntry(session_options, kOrtSessionOptionEpContextEmbedMode, "1");
# Python
options.add_session_config_entry("ep.context_embed_mode", "1")
QNN EP 權重共享
注意:QNN EP 需要 Linux x86_64 或 Windows x86_64 平臺。
此外,如果使用者使用 QNN 工具鏈 (qnn-context-binary-generator) 建立帶有權重共享的 QNN 上下文二進位制檔案 (qnn_ctx.bin),他們可以使用指令碼從該上下文生成包裝 Onnx 模型:gen_qnn_ctx_onnx_model.py。該指令碼會建立多個 model_x_ctx.onnx 檔案,每個檔案都包含一個引用共享 qnn_ctx.bin 檔案的 EPContext 節點。每個 EPContext 節點指定一個唯一的節點名稱,引用 QNN 上下文中的不同 Qnn 圖。
用法
C++
C API 詳情請見此處。
Ort::Env env = Ort::Env{ORT_LOGGING_LEVEL_ERROR, "Default"};
std::unordered_map<std::string, std::string> qnn_options;
qnn_options["backend_path"] = "QnnHtp.dll";
Ort::SessionOptions session_options;
session_options.AppendExecutionProvider("QNN", qnn_options);
Ort::Session session(env, model_path, session_options);
Python
import onnxruntime as ort
# Create a session with QNN EP using HTP (NPU) backend.
sess = ort.InferenceSession(model_path, providers=['QNNExecutionProvider'], provider_options=[{'backend_path':'QnnHtp.dll'}])`
推理示例
使用 QNN 執行提供者在 CPP 中使用 QNN CPU 和 HTP 後端進行 Mobilenetv2 影像分類
錯誤處理
HTP 子系統重啟 - SSR
QNN EP 返回 StatusCode::ENGINE_ERROR,表示 QNN HTP SSR 問題。如果在會話執行期間檢測到此錯誤,上層框架/應用程式應重新建立 Onnxruntime 會話。
在 QNN EP 中新增新運算子支援
要在 EP 中啟用新運算子支援,需要關注以下方面
- QDQ 指令碼是否支援此操作?程式碼示例
- Onnxruntime QDQ 節點單元是否支援此操作?程式碼示例
- 它是否是佈局敏感運算子?
- 是否在 LayoutTransformer 中註冊?程式碼示例
- NHWC 運算子模式已註冊?示例錯誤訊息
::operator ()] 模型 face_det_qdq 載入失敗:致命錯誤:com.ms.internal.nhwc:BatchNormalization(9) 不是已註冊的函式/操作 [示例 PR](https://github.com/microsoft/onnxruntime/pull/15278)
啟用新運算子的 PR 示例
-
非佈局敏感運算子。 使用 SDK 直接支援為 QNN EP 啟用 Hardsigmoid
混合精度支援
下圖展示了一個混合精度模型的示例。
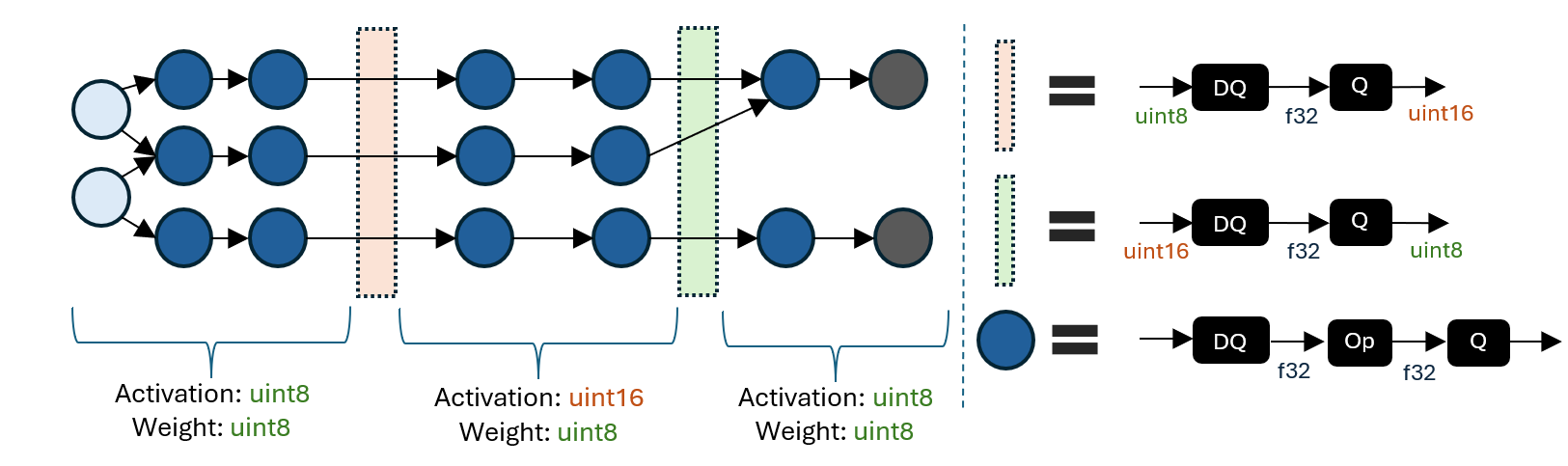
混合精度 QDQ 模型由具有不同啟用/權重量化資料型別的區域組成。區域之間的邊界使用 DQ 到 Q 序列在啟用量化資料型別(例如,uint8 到 uint16)之間進行轉換。
指定不同量化資料型別區域的能力使得探索精度和延遲之間的權衡成為可能。更高的整數精度可能會提高精度,但會犧牲延遲,因此有選擇地將某些區域提升到更高的精度有助於在關鍵指標上實現理想的平衡。
下圖顯示了一個模型,其中一個區域已從預設的 8 位啟用型別提升到 16 位。
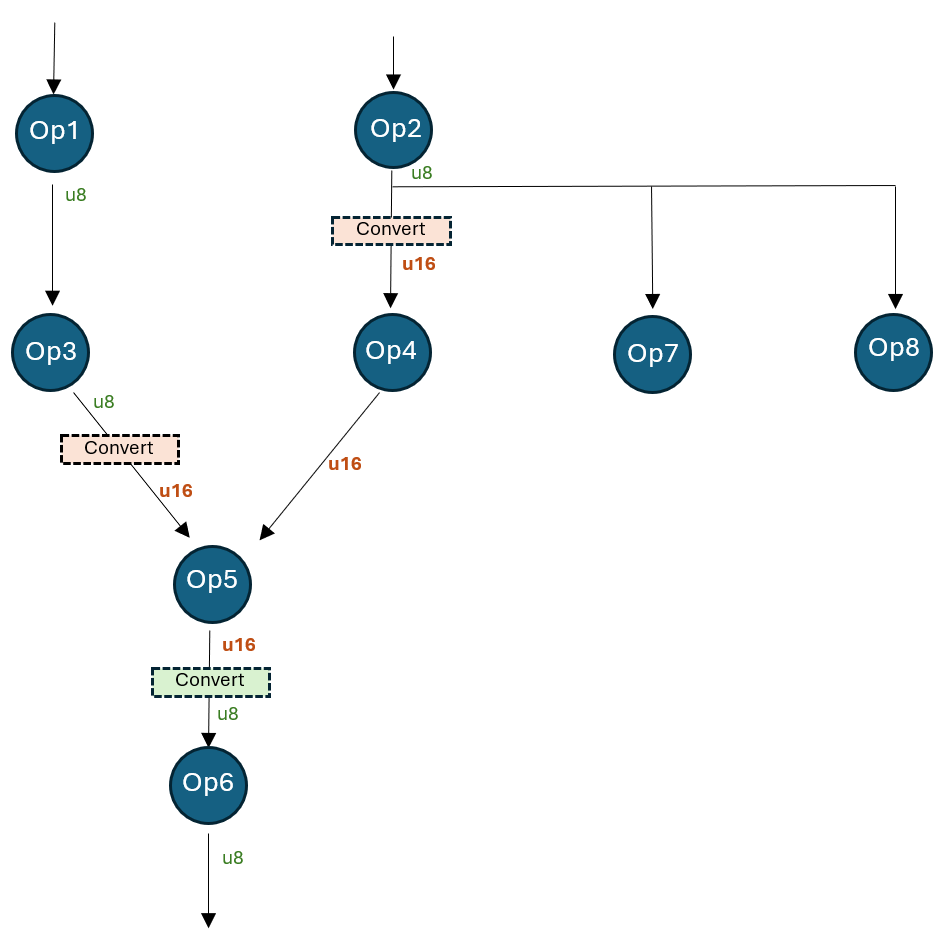
該模型量化為 uint8 精度,但張量“Op4_out”量化為 16 位。這可以透過指定以下初始張量量化覆蓋來實現
# Op4_out could be an inaccurate tensor that should be upgraded to 16bit
initial_overrides = {"Op4_out": [{"quant_type": QuantType.QUInt16}]}
qnn_config = get_qnn_qdq_config(
float_model_path,
data_reader,
activation_type=QuantType.QUInt8,
weight_type=QuantType.QUInt8,
init_overrides=initial_overrides, # These initial overrides will be "fixed"
)
上述程式碼片段生成以下“固定”覆蓋(透過 qnn_config.extra_options[“TensorQuantOverrides”] 獲取)
overrides = {
“Op2_out”: [{“quant_type”: QUInt8, “convert”: {“quant_type”: QUInt16, “recv_nodes”: {“Op4”}}}],
“Op3_out”: [{“quant_type”: QUInt8, “convert”: {“quant_type”: QUInt16, “recv_nodes”: {“Op5”}}}],
“Op4_out”: [{“quant_type”: QUInt16}],
“Op5_out”: [{“quant_type”: QUInt16, “convert”: {“quant_type”: QUInt8, “recv_nodes”: {“Op6”}}}]
}
覆蓋後,模型工作方式如下
- Op2 的輸出由 Op4、Op7 和 Op8 消耗。Op4 消耗轉換後的 u16 型別,而 Op7 和 Op8 消耗原始的 u8 型別。
- Op3 的輸出從 u8 轉換為 u16。Op5 消耗轉換後的 u16 型別。
- Op4 的輸出只是 u16(未轉換)。
- Op5 的輸出從 u16 轉換為 u8。Op6 消耗 u8 型別。
LoRAv2 支援
目前,僅支援帶有 EPContext 節點的預編譯模型。參考示例指令碼為 gen_qnn_ctx_onnx_model.py。在使用 QNN SDK 應用 LoRAv2 模型後,將生成一個主 QNN 上下文二進位制檔案和多個介面卡二進位制段。我們使用 LoRAv2 配置並將其放入 RunOptions 中進行推理。
- LoRAv2 配置的格式
- graph name: QNN 預構建上下文二進位制檔案中的 QNN 圖。
- adapter binary section path: 由 qnn-context-binary-generator 生成的二進位制段 ```