自定義運算元
ONNX Runtime 提供了執行非官方 ONNX 運算元的自定義運算元選項。請注意,自定義運算元與 貢獻運算元 不同,後者是直接內建到 ORT 中的選定非官方 ONNX 運算元。
目錄
- 定義和註冊自定義運算元
- 自定義運算元開發和註冊的舊方式
- 建立自定義運算元庫
- 從自定義運算元呼叫原生運算元
- 用於 CUDA 和 ROCM 的自定義運算元
- 一個運算元,多種型別
- 在自定義運算元中封裝外部推理執行時
定義和註冊自定義運算元
自 onnxruntime 1.16 起,自定義運算元可以簡單地實現為函式
void KernelOne(const Ort::Custom::Tensor<float>& X,
const Ort::Custom::Tensor<float>& Y,
Ort::Custom::Tensor<float>& Z) {
auto input_shape = X.Shape();
auto x_raw = X.Data();
auto y_raw = Y.Data();
auto z_raw = Z.Allocate(input_shape);
for (int64_t i = 0; i < Z.NumberOfElement(); ++i) {
z_raw[i] = x_raw[i] + y_raw[i];
}
}
int main() {
Ort::CustomOpDomain v1_domain{"v1"};
// please make sure that custom_op_one has the same lifetime as the consuming session
std::unique_ptr<OrtLiteCustomOp> custom_op_one{Ort::Custom::CreateLiteCustomOp("CustomOpOne", "CPUExecutionProvider", KernelOne)};
v1_domain.Add(custom_op_one.get());
Ort::SessionOptions session_options;
session_options.Add(v1_domain);
// create a session with the session_options ...
}
對於帶有屬性的自定義運算元,也支援結構體:
struct Merge {
Merge(const OrtApi* ort_api, const OrtKernelInfo* info) {
int64_t reverse;
ORT_ENFORCE(ort_api->KernelInfoGetAttribute_int64(info, "reverse", &reverse) == nullptr);
reverse_ = reverse != 0;
}
// a "Compute" member function is required to be present
void Compute(const Ort::Custom::Tensor<std::string_view>& strings_in,
std::string_view string_in,
Ort::Custom::Tensor<std::string>* strings_out) {
std::vector<std::string> string_pool;
for (const auto& s : strings_in.Data()) {
string_pool.emplace_back(s.data(), s.size());
}
string_pool.emplace_back(string_in.data(), string_in.size());
if (reverse_) {
for (auto& str : string_pool) {
std::reverse(str.begin(), str.end());
}
std::reverse(string_pool.begin(), string_pool.end());
}
strings_out->SetStringOutput(string_pool, {static_cast<int64_t>(string_pool.size())});
}
bool reverse_ = false;
};
int main() {
Ort::CustomOpDomain v2_domain{"v2"};
// please make sure that mrg_op_ptr has the same lifetime as the consuming session
std::unique_ptr<Ort::Custom::OrtLiteCustomOp> mrg_op_ptr{Ort::Custom::CreateLiteCustomOp<Merge>("Merge", "CPUExecutionProvider")};
v2_domain.Add(mrg_op_ptr.get());
Ort::SessionOptions session_options;
session_options.Add(v2_domain);
// create a session with the session_options ...
}
結構體需要一個 “Compute” 成員函式才能作為自定義運算元執行。
對於這兩種情況
- 輸入需要宣告為 const 引用。
- 輸出需要宣告為非 const 引用。
- Ort::Custom::Tensor::Shape() 返回輸入形狀。
- Ort::Custom::Tensor::Data() 返回原始輸入資料。
- Ort::Custom::Tensor::NumberOfElement() 返回輸入中的元素數量。
- Ort::Custom::Tensor::Allocate(…) 分配一個輸出並返回原始資料地址。
- 支援的模板引數有:int8_t, int16_t, int32_t, int64_t, float, double。
- 支援 std::string_view 作為輸入和 std::string 作為輸出,請在 此處 查詢用法。
- 對於在 CPUExecutionProvider 上執行的自定義運算元函式,支援 span 和 scalar 作為輸入,請在 此處 查詢用法。
- 對於需要核心上下文的自定義運算元函式,請在 此處 檢視示例。
- 當使用 unique_ptr 託管建立的自定義運算元時,請務必使其與消費會話保持活躍。
自定義運算元開發和註冊的舊方式
開發自定義運算元的舊方式仍然受支援,請參考 此處 的示例。
建立自定義運算元庫
自定義運算元可以在單獨的共享庫中定義(例如,Windows 上的 .dll 或 Linux 上的 .so)。自定義運算元庫必須匯出並實現 RegisterCustomOps 函式。RegisterCustomOps 函式將包含庫自定義運算元的 Ort::CustomOpDomain 新增到提供的會話選項中。請參考 此處 的專案和 此處 相關的 cmake 命令。
從自定義運算元呼叫原生運算元
為了簡化自定義運算元的實現,可以直接呼叫原生 onnxruntime 運算元。例如,某些自定義運算元可能需要在其他計算之間執行 GEMM 或 TopK。這對於節點(如 Conv)的預處理和後處理也很有用,例如用於狀態管理目的。為此,Conv 節點可以被自定義運算元(如 CustomConv)包裝,在其中可以快取和處理輸入和輸出。
此功能從 ONNX Runtime 1.12.0+ 開始支援。參見:API 和 示例。
用於 CUDA 和 ROCM 的自定義運算元
自 onnxruntime 1.16 起,支援用於 CUDA 和 ROCM 裝置的自定義運算元。裝置相關資源可以透過裝置相關上下文直接從運算元內部訪問。以 CUDA 為例
void KernelOne(const Ort::Custom::CudaContext& cuda_ctx,
const Ort::Custom::Tensor<float>& X,
const Ort::Custom::Tensor<float>& Y,
Ort::Custom::Tensor<float>& Z) {
auto input_shape = X.Shape();
CUSTOM_ENFORCE(cuda_ctx.cuda_stream, "failed to fetch cuda stream");
CUSTOM_ENFORCE(cuda_ctx.cudnn_handle, "failed to fetch cudnn handle");
CUSTOM_ENFORCE(cuda_ctx.cublas_handle, "failed to fetch cublas handle");
auto z_raw = Z.Allocate(input_shape);
cuda_add(Z.NumberOfElement(), z_raw, X.Data(), Y.Data(), cuda_ctx.cuda_stream); // launch a kernel inside
}
完整示例可在 此處 找到。為進一步方便開發,透過 CudaContext 公開各種 cuda ep 資源和配置,詳情請參考 標頭檔案。
對於 ROCM,它是這樣的
void KernelOne(const Ort::Custom::RocmContext& rocm_ctx,
const Ort::Custom::Tensor<float>& X,
const Ort::Custom::Tensor<float>& Y,
Ort::Custom::Tensor<float>& Z) {
auto input_shape = X.Shape();
CUSTOM_ENFORCE(rocm_ctx.hip_stream, "failed to fetch hip stream");
CUSTOM_ENFORCE(rocm_ctx.miopen_handle, "failed to fetch miopen handle");
CUSTOM_ENFORCE(rocm_ctx.rblas_handle, "failed to fetch rocblas handle");
auto z_raw = Z.Allocate(input_shape);
rocm_add(Z.NumberOfElement(), z_raw, X.Data(), Y.Data(), rocm_ctx.hip_stream); // launch a kernel inside
}
詳細資訊可在 此處 找到。
一個運算元,多種型別
自 onnxruntime 1.16 起,自定義運算元允許支援多種資料型別
template <typename T>
void MulTop(const Ort::Custom::Span<T>& in, Ort::Custom::Tensor<T>& out) {
out.Allocate({1})[0] = in[0] * in[1];
}
int main() {
std::unique_ptr<OrtLiteCustomOp> c_MulTopOpFloat{Ort::Custom::CreateLiteCustomOp("MulTop", "CPUExecutionProvider", MulTop<float>)};
std::unique_ptr<OrtLiteCustomOp> c_MulTopOpInt32{Ort::Custom::CreateLiteCustomOp("MulTop", "CPUExecutionProvider", MulTop<int32_t>)};
// create a domain adding both c_MulTopOpFloat and c_MulTopOpInt32
}
在自定義運算元中封裝外部推理執行時
自定義運算元可以封裝整個模型,然後透過外部 API 或執行時進行推理。這有助於將外部推理引擎或 API 與 ONNX Runtime 整合。
例如,考慮以下 ONNX 模型,其中包含一個名為“OpenVINO_Wrapper”的自定義運算元。“OpenVINO_Wrapper”節點以 OpenVINO 的原生模型格式(XML 和 BIN 資料)封裝了一個完整的 MNIST 模型。模型資料被序列化到節點的屬性中,然後由自定義運算元的核心檢索,以構建模型的記憶體表示並使用 OpenVINO C++ API 執行推理。
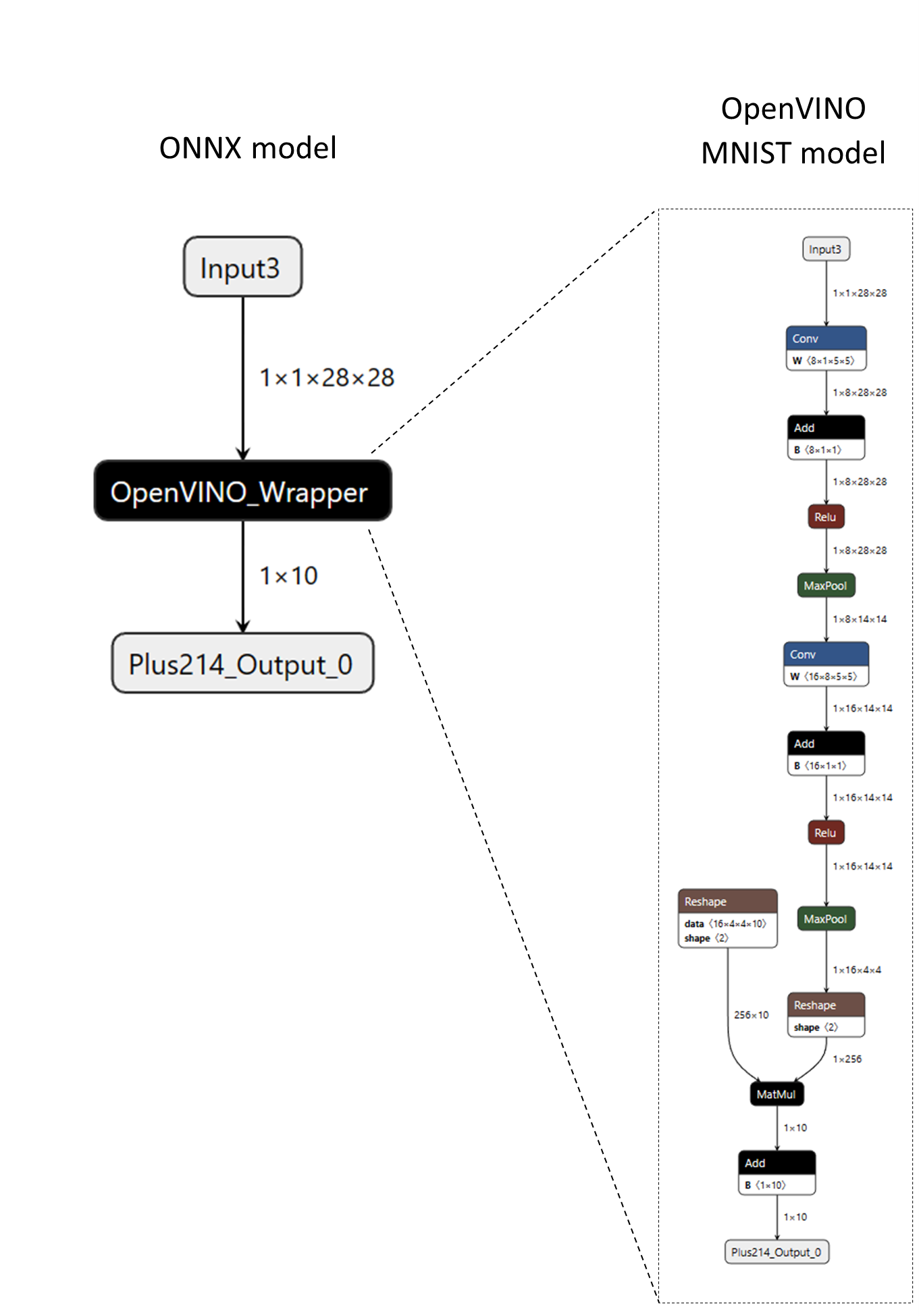
以下程式碼片段展示瞭如何定義自定義運算元。
// Note - below code utilizes legacy custom op interfaces
struct CustomOpOpenVINO : Ort::CustomOpBase<CustomOpOpenVINO, KernelOpenVINO> {
explicit CustomOpOpenVINO(Ort::ConstSessionOptions session_options);
CustomOpOpenVINO(const CustomOpOpenVINO&) = delete;
CustomOpOpenVINO& operator=(const CustomOpOpenVINO&) = delete;
void* CreateKernel(const OrtApi& api, const OrtKernelInfo* info) const;
constexpr const char* GetName() const noexcept {
return "OpenVINO_Wrapper";
}
constexpr const char* GetExecutionProviderType() const noexcept {
return "CPUExecutionProvider";
}
// IMPORTANT: In order to wrap a generic runtime-specific model, the custom operator
// must have a single non-homogeneous variadic input and output.
constexpr size_t GetInputTypeCount() const noexcept {
return 1;
}
constexpr size_t GetOutputTypeCount() const noexcept {
return 1;
}
constexpr ONNXTensorElementDataType GetInputType(size_t /* index */) const noexcept {
return ONNX_TENSOR_ELEMENT_DATA_TYPE_UNDEFINED;
}
constexpr ONNXTensorElementDataType GetOutputType(size_t /* index */) const noexcept {
return ONNX_TENSOR_ELEMENT_DATA_TYPE_UNDEFINED;
}
constexpr OrtCustomOpInputOutputCharacteristic GetInputCharacteristic(size_t /* index */) const noexcept {
return INPUT_OUTPUT_VARIADIC;
}
constexpr OrtCustomOpInputOutputCharacteristic GetOutputCharacteristic(size_t /* index */) const noexcept {
return INPUT_OUTPUT_VARIADIC;
}
constexpr bool GetVariadicInputHomogeneity() const noexcept {
return false; // heterogenous
}
constexpr bool GetVariadicOutputHomogeneity() const noexcept {
return false; // heterogeneous
}
// The "device_type" is configurable at the session level.
std::vector<std::string> GetSessionConfigKeys() const { return {"device_type"}; }
private:
std::unordered_map<std::string, std::string> session_configs_;
};
請注意,自定義運算元被定義為具有單個變長/異構輸入和單個變長/異構輸出。這是為了能夠封裝具有不同輸入和輸出型別和形狀的 OpenVINO 模型(而不僅僅是 MNIST 模型)。有關輸入和輸出特徵的更多資訊,請參閱 OrtCustomOp 結構體文件。
此外,自定義運算元宣告“device_type”為一個會話配置,可由應用程式設定。以下程式碼片段展示瞭如何註冊和配置包含上述自定義運算元的自定義運算元庫。
Ort::Env env;
Ort::SessionOptions session_options;
Ort::CustomOpConfigs custom_op_configs;
// Create local session config entries for the custom op.
custom_op_configs.AddConfig("OpenVINO_Wrapper", "device_type", "CPU");
// Register custom op library and pass in the custom op configs (optional).
session_options.RegisterCustomOpsLibrary("MyOpenVINOWrapper_Lib.so", custom_op_configs);
Ort::Session session(env, ORT_TSTR("custom_op_mnist_ov_wrapper.onnx"), session_options);
有關更多詳細資訊,請參閱 完整的 OpenVINO 自定義運算元封裝示例。要建立封裝外部模型或權重的 ONNX 模型,請參閱 create_custom_op_wrapper.py 工具。