量化 ONNX 模型
目錄
量化概述
ONNX Runtime 中的量化是指 ONNX 模型的 8 位線性量化。
在量化過程中,浮點值被對映到 8 位量化空間,形式為:val_fp32 = scale * (val_quantized - zero_point)
scale 是一個正實數,用於將浮點數對映到量化空間。其計算方法如下:
對於非對稱量化
scale = (data_range_max - data_range_min) / (quantization_range_max - quantization_range_min)
對於對稱量化
scale = max(abs(data_range_max), abs(data_range_min)) * 2 / (quantization_range_max - quantization_range_min)
zero_point 表示量化空間中的零點。重要的是,浮點零值必須在量化空間中精確表示。這是因為許多 CNN 中都使用零填充。如果量化後無法唯一表示 0,則會導致精度誤差。
ONNX 量化表示格式
有兩種方式表示量化的 ONNX 模型
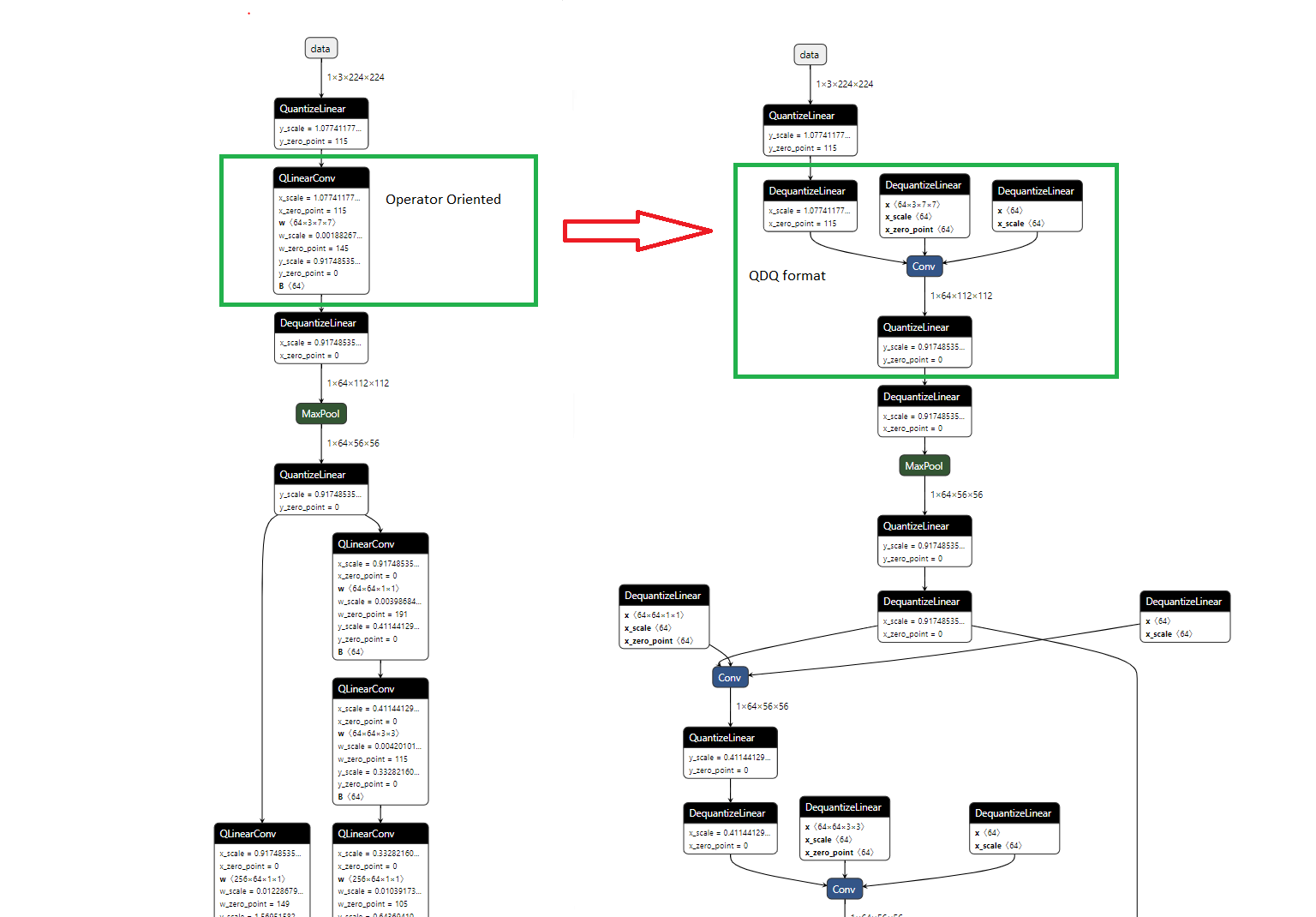
- 面向運算子(QOperator)
所有量化後的運算子都有其自己的 ONNX 定義,例如 QLinearConv、MatMulInteger 等。 - 面向張量(QDQ;Quantize and DeQuantize)
這種格式在原始運算子之間插入 DeQuantizeLinear(QuantizeLinear(tensor)) 以模擬量化和反量化過程。
在靜態量化中,QuantizeLinear 和 DeQuantizeLinear 運算子也帶有量化引數。
在動態量化中,會插入一個 ComputeQuantizationParameters 函式原型來動態計算量化引數。 - 透過以下方式生成的模型採用 QDQ 格式
- 透過 quantize_static(下文解釋)且
quant_format=QuantFormat.QDQ進行量化的模型。 - 從 Tensorflow 轉換或從 PyTorch 匯出的量化感知訓練 (QAT) 模型。
- 從 TFLite 和其他框架轉換的量化模型。
- 透過 quantize_static(下文解釋)且
對於後兩種情況,您無需使用量化工具對模型進行量化。ONNX Runtime 可以直接將它們作為量化模型執行。
下圖顯示了量化 Conv 的 QOperator 和 QDQ 格式的等效表示。這個端到端示例演示了這兩種格式。
量化 ONNX 模型
ONNX Runtime 提供 Python API,用於將 32 位浮點模型轉換為 8 位整數模型,即量化。這些 API 包括預處理、動態/靜態量化和除錯。
預處理
預處理是將 float32 模型轉換為準備好進行量化的過程。它包括以下三個可選步驟:
- 符號形狀推斷。這最適合 Transformer 模型。
- 模型最佳化:此步驟使用 ONNX Runtime 本機庫重寫計算圖,包括合併計算節點、消除冗餘以提高執行時效率。
- ONNX 形狀推斷。
這些步驟的目標是提高量化質量。當張量形狀已知時,我們的量化工具效果最佳。符號形狀推斷和 ONNX 形狀推斷都有助於確定張量形狀。符號形狀推斷最適用於基於 Transformer 的模型,而 ONNX 形狀推斷適用於其他模型。
模型最佳化執行某些運算子融合,使量化工具的工作更輕鬆。例如,一個卷積運算子後跟批歸一化可以在最佳化過程中融合為一個,從而可以非常高效地進行量化。
不幸的是,ONNX Runtime 的一個已知問題是模型最佳化無法輸出大於 2GB 的模型。因此,對於大型模型,必須跳過最佳化。
預處理 API 位於 Python 模組 onnxruntime.quantization.shape_inference 中的函式 quant_pre_process()。請參閱 shape_inference.py。要了解有關預處理的更多選項和更精細的控制,請執行以下命令:
python -m onnxruntime.quantization.preprocess --help
模型最佳化也可以在量化期間進行。然而,即使由於歷史原因這是預設行為,但不推薦這樣做。量化期間的模型最佳化會給除錯由量化引起的精度損失帶來困難,這將在後續章節中討論。因此,最好在預處理期間而不是在量化期間執行模型最佳化。
動態量化
模型量化有兩種方式:動態量化和靜態量化。動態量化動態計算啟用的量化引數(縮放因子和零點)。這些計算會增加推理成本,但通常比靜態量化能獲得更高的精度。
動態量化的 Python API 位於模組 onnxruntime.quantization.quantize 中的函式 quantize_dynamic()。
靜態量化
靜態量化方法首先使用一組稱為校準資料(calibration data)的輸入執行模型。在這些執行期間,我們計算每個啟用的量化引數。這些量化引數作為常量寫入到量化模型中,並用於所有輸入。我們的量化工具支援三種校準方法:MinMax、Entropy 和 Percentile。請參閱 calibrate.py 瞭解詳細資訊。
靜態量化的 Python API 位於模組 onnxruntime.quantization.quantize 中的函式 quantize_static()。請參閱 quantize.py 瞭解詳細資訊。
量化除錯
量化並非無損轉換。它可能會對模型的精度產生負面影響。解決此問題的方法是比較原始計算圖與量化後計算圖的權重和啟用張量,找出它們差異最大的地方,並避免量化這些張量,或者選擇其他量化/校準方法。這被稱為量化除錯。為了方便此過程,我們提供了 Python API,用於匹配 float32 模型及其量化對應模型的權重和啟用張量。
除錯 API 位於模組 onnxruntime.quantization.qdq_loss_debug,它具有以下功能:
- 函式
create_weight_matching()。它接受一個 float32 模型及其量化模型,並輸出一個字典,用於匹配這兩個模型之間對應的權重。 - 函式
modify_model_output_intermediate_tensors()。它接受一個 float32 或量化模型,並對其進行增強以儲存所有啟用。 - 函式
collect_activations()。它接受一個由modify_model_output_intermediate_tensors()增強的模型和一個輸入資料讀取器,執行增強模型以收集所有啟用。 - 函式
create_activation_matching()。您可以想象您在 float32 模型及其量化模型上都執行collect_activations(modify_model_output_intermediate_tensors()),以收集兩組啟用。此函式接受這兩組啟用,並匹配相應的啟用,以便使用者可以輕鬆比較它們。
總而言之,ONNX Runtimes 提供了 Python API,用於匹配 float32 模型及其量化對應模型之間的相應權重和啟用張量。這允許使用者輕鬆比較它們,以找到最大的差異所在。
然而,量化期間的模型最佳化會給這個除錯過程帶來困難,因為它可能會顯著改變計算圖,導致量化模型與原始模型截然不同。這使得匹配來自兩個模型的相應張量變得困難。因此,我們建議在預處理期間而不是量化過程中執行模型最佳化。
示例
- 動態量化
import onnx
from onnxruntime.quantization import quantize_dynamic, QuantType
model_fp32 = 'path/to/the/model.onnx'
model_quant = 'path/to/the/model.quant.onnx'
quantized_model = quantize_dynamic(model_fp32, model_quant)
- 靜態量化:請參閱端到端示例。
方法選擇
動態量化和靜態量化之間的主要區別在於啟用的縮放因子和零點如何計算。對於靜態量化,它們是預先(離線)使用校準資料集計算的。因此,啟用在每個前向傳播中都具有相同的縮放因子和零點。對於動態量化,它們是即時(線上)計算的,並且特定於每個前向傳播。因此,它們更準確,但會引入額外的計算開銷。
一般來說,對於 RNN 和基於 Transformer 的模型,建議使用動態量化;對於 CNN 模型,建議使用靜態量化。
如果兩種訓練後量化方法都無法達到您的精度目標,您可以嘗試使用量化感知訓練 (QAT) 來重新訓練模型。ONNX Runtime 目前不提供再訓練功能,但您可以使用原始框架重新訓練模型並將其轉換回 ONNX。
資料型別選擇
量化值是 8 位寬,可以是帶符號(int8)或無符號(uint8)的。我們可以分別選擇啟用和權重的符號性,因此資料格式可以是(啟用:uint8,權重:uint8),(啟用:uint8,權重:int8)等。我們用 U8U8 作為(啟用:uint8,權重:uint8)的簡稱,U8S8 作為(啟用:uint8,權重:int8)的簡稱,S8U8 和 S8S8 以此類推用於剩餘兩種格式。
ONNX Runtime 在 CPU 上的量化可以執行 U8U8、U8S8 和 S8S8。S8S8 和 QDQ 是預設設定,並在效能和精度之間取得平衡。它應該是首選。只有在精度下降很多的情況下,您可以嘗試 U8U8。請注意,QOperator 的 S8S8 在 x86-64 CPU 上會很慢,通常應避免使用。ONNX Runtime 在 GPU 上的量化僅支援 S8S8。
我何時以及為何需要嘗試 U8U8?
在具有 AVX2 和 AVX512 擴充套件的 x86-64 機器上,ONNX Runtime 使用 VPMADDUBSW 指令進行 U8S8 以提高效能。此指令可能會出現飽和問題:輸出可能無法容納 16 位整數,並且必須被鉗位(飽和)以適應。通常,這對最終結果影響不大。但是,如果您確實遇到較大的精度下降,則可能是由飽和引起的。在這種情況下,您可以嘗試 reduce_range 或 U8U8 格式,後者沒有飽和問題。
在其他 CPU 架構(帶 VNNI 的 x64 和 Arm®)上沒有此類問題。
支援的量化操作列表
請參閱 登錄檔 以獲取支援的操作列表。
量化和模型 opset 版本
模型必須是 opset10 或更高版本才能進行量化。opset < 10 的模型必須使用更新的 opset 從其原始框架重新轉換為 ONNX。
基於 Transformer 的模型
針對基於 Transformer 的模型有一些特定的最佳化,例如用於量化注意力層的 QAttention。為了利用這些最佳化,您需要在量化模型之前,使用 Transformer 模型最佳化工具最佳化您的模型。
此筆記本演示了整個過程。
GPU 上的量化
在 GPU 上實現量化更好的效能需要硬體支援。您需要一個支援 Tensor Core int8 計算的裝置,例如 T4 或 A100。舊硬體無法從量化中受益。
ONNX Runtime 現在利用 TensorRT 執行提供程式在 GPU 上進行量化。與 CPU 執行提供程式不同,TensorRT 接受全精度模型和輸入的校準結果。它根據自己的邏輯決定如何量化。利用 TensorRT EP 量化的總體流程是:
- 實現 CalibrationDataReader。
- 使用校準資料集計算量化引數。注意:為了包含模型中所有張量以實現更好的校準,請先執行
symbolic_shape_infer.py。請參閱此處瞭解詳細資訊。 - 將量化引數儲存到 flatbuffer 檔案中
- 載入模型和量化引數檔案,並使用 TensorRT EP 執行。
我們提供了兩個端到端示例:Yolo V3 和 resnet50。
量化到 Int4/UInt4
ONNX Runtime 可以將模型中的某些運算子量化為 4 位整數型別。對這些運算子應用塊級僅權重(weight-only)量化。支援的運算子型別有:
- MatMul:
- 僅當輸入
B為常量時,節點才會被量化 - 支援 QOperator 或 QDQ 格式。
- 如果選擇了 QOperator,節點將轉換為 MatMulNBits 節點。權重
B將進行塊級量化並儲存到新節點中。支援 HQQ、GPTQ 和 RTN(預設)演算法。 - 如果選擇了 QDQ,MatMul 節點將替換為 DequantizeLinear -> MatMul 對。權重
B將進行塊級量化並作為初始化器儲存在 DequantizeLinear 節點中。
- 僅當輸入
- Gather:
- 僅當輸入
data為常量時,節點才會被量化。 - 支援 QOperator
- Gather 量化為 GatherBlockQuantized 節點。輸入
data將進行塊級量化並儲存到新節點中。僅支援 RTN 演算法。
- 僅當輸入
由於 Int4/UInt4 型別在 onnx opset 21 中引入,如果模型的 onnx 域版本 < 21,它將被強制升級到 opset 21。請確保模型中的運算子與 onnx opset 21 相容。
要執行包含 GatherBlockQuantized 節點的模型,需要 ONNX Runtime 1.20。
程式碼示例
from onnxruntime.quantization import (
matmul_4bits_quantizer,
quant_utils,
quantize
)
from pathlib import Path
model_fp32_path="path/to/orignal/model.onnx"
model_int4_path="path/to/save/quantized/model.onnx"
quant_config = matmul_4bits_quantizer.DefaultWeightOnlyQuantConfig(
block_size=128, # 2's exponential and >= 16
is_symmetric=True, # if true, quantize to Int4. otherwise, quantize to uint4.
accuracy_level=4, # used by MatMulNbits, see https://github.com/microsoft/onnxruntime/blob/main/docs/ContribOperators.md#attributes-35
quant_format=quant_utils.QuantFormat.QOperator,
op_types_to_quantize=("MatMul","Gather"), # specify which op types to quantize
quant_axes=(("MatMul", 0), ("Gather", 1),) # specify which axis to quantize for an op type.
model = quant_utils.load_model_with_shape_infer(Path(model_fp32_path))
quant = matmul_4bits_quantizer.MatMul4BitsQuantizer(
model,
nodes_to_exclude=None, # specify a list of nodes to exclude from quantization
nodes_to_include=None, # specify a list of nodes to force include from quantization
algo_config=quant_config,)
quant.process()
quant.model.save_model_to_file(
model_int4_path,
True) # save data to external file
有關 AWQ 和 GTPQ 量化用法,請參閱 Gen-AI 模型構建器。
常見問題
為什麼我沒有看到效能提升?
效能提升取決於您的模型和硬體。量化帶來的效能提升有兩個方面:計算和記憶體。舊硬體沒有或很少有執行 int8 高效推理所需的指令。而且量化有開銷(來自量化和反量化),因此在舊裝置上獲得更差的效能並非罕見。
支援 VNNI 的 x86-64、支援 Tensor Core int8 的 GPU 以及支援點積指令的 Arm® 處理器通常可以獲得更好的效能。
我應該選擇哪種量化方法,動態量化還是靜態量化?
請參閱方法選擇一節。
何時使用 reduce-range 和逐通道量化?
Reduce-range 會將權重量化為 7 位。它專為 AVX2 和 AVX512(非 VNNI)機器上的 U8S8 格式設計,以緩解飽和問題。在支援 VNNI 的機器上則不需要。
對於權重範圍較大的模型,逐通道量化可以提高精度。如果精度損失較大,請嘗試使用它。在 AVX2 和 AVX512 機器上,如果啟用逐通道量化,通常還需要啟用 reduce-range。
為什麼像 MaxPool 這樣的運算子沒有被量化?
ONNX opset 12 中增加了對 MaxPool 等某些運算子的 8 位型別支援。請檢查您的模型版本並將其升級到 opset 12 及以上。