如何使用 ONNX Runtime 開發移動應用程式
ONNX Runtime 為您提供了多種選項,可以將機器學習新增到您的移動應用程式中。本頁面概述了開發流程。您也可以檢視本節中的教程
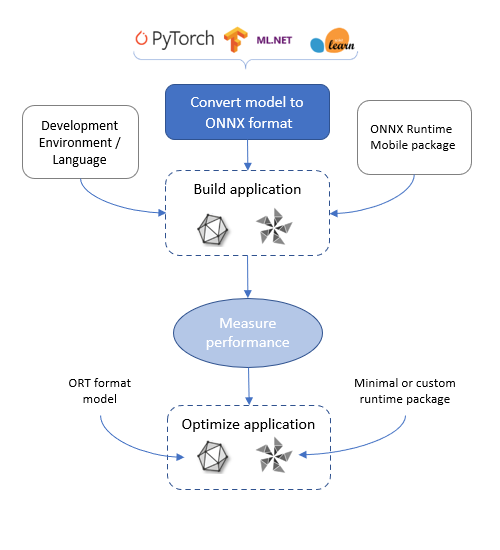
ONNX Runtime 移動應用程式開發流程
獲取模型
開發您的移動機器學習應用程式的第一步是獲取模型。
您需要了解您的移動應用程式場景,並獲取一個適合該場景的 ONNX 模型。例如,應用程式是分類影像、在影片流中進行目標檢測、總結或預測文字,還是進行數值預測。
要在 ONNX Runtime 移動版上執行,模型需要採用 ONNX 格式。ONNX 模型可以從 ONNX 模型庫獲取。如果您的模型尚未採用 ONNX 格式,您可以使用其中一個轉換器將其從 PyTorch、TensorFlow 和其他格式轉換為 ONNX。
由於模型是在裝置上載入和執行的,因此模型必須適應裝置磁碟並能夠載入到裝置的記憶體中。
開發應用程式
一旦有了模型,您就可以使用 ONNX Runtime API 載入並執行它。
您使用的語言繫結和執行時包取決於您選擇的開發環境和您正在開發的目標。
- Android Java/C/C++: onnxruntime-android 包
- iOS C/C++: onnxruntime-c 包
- iOS Objective-C: onnxruntime-objc 包
- MAUI/Xamarin 中的 Android 和 iOS C#: Microsoft.ML.OnnxRuntime 和 Microsoft.ML.OnnxRuntime.Managed
有關包的具體說明,請參閱安裝指南。
上述所有包都包含完整的 ONNX Runtime 功能和運算子集,並支援 ONNX 格式。我們建議您從這些包開始開發您的應用程式。可能需要進一步最佳化,詳細資訊如下。
根據目標平臺,您可以在應用程式中選擇使用不同的硬體加速器
- 所有目標都支援 CPU,這是預設設定
- 在 Android 上執行的應用程式還支援 NNAPI 和 XNNPACK
- 在 iOS 上執行的應用程式還支援 CoreML 和 XNNPACK
加速器在 ONNX Runtime 中稱為執行提供程式(Execution Providers)。
如果模型是量化模型,請從 CPU 執行提供程式開始。如果模型未量化,請從 XNNPACK 開始。這些是最簡單、最一致的,因為所有內容都在 CPU 上執行。
如果 CPU/XNNPACK 不滿足應用程式的效能要求,請嘗試 NNAPI/CoreML。這些執行提供程式的效能取決於裝置和模型。如果模型由於使用了執行提供程式不支援的運算子(例如,由於較舊的 NNAPI 版本)而被拆分為多個分割槽,則效能可能會下降。
在建立 ONNXRuntime 會話並載入模型時,會在 SessionOptions 中配置特定的執行提供程式。有關更多詳細資訊,請參閱您的語言API 文件。
測量應用程式效能
根據目標平臺的要求測量應用程式的效能。這包括
- 應用程式二進位制大小
- 模型大小
- 應用程式延遲
- 功耗
如果應用程式不符合其要求,可以應用最佳化。
最佳化您的應用程式
減小模型大小
減小模型大小的一種方法是量化模型。這會將一個原始的 32 位權重的模型縮小約 4 倍,因為權重被減小到 8 位。有關操作說明,請參閱 ONNX Runtime 量化指南。
另一種減小模型大小的方法是找到一個具有相同輸入、輸出和架構,並且已經針對移動裝置進行最佳化的新模型。例如:MobileNet 和 MobileBert。
減小應用程式二進位制大小
為了減小 ONNX Runtime 二進位制檔案的大小,您可以根據您的模型構建一個自定義執行時。
請參閱構建自定義執行時的過程。
ORT 格式轉換的輸出之一是構建配置檔案,其中包含模型的運算子列表及其型別。您可以將此配置檔案作為輸入用於自定義執行時二進位制構建。
為了讓您瞭解預構建包和自定義構建之間的二進位制大小差異
| 檔案 | 1.18.0 預構建包大小 (位元組) | 1.18.0 自定義構建大小 (位元組) |
|---|---|---|
| AAR | 24415212 | 7532309 |
jni/arm64-v8a/libonnxruntime.so,未壓縮 | 16276832 | 3962832 |
jni/x86_64/libonnxruntime.so,未壓縮 | 18222208 | 4240864 |
此自定義構建支援執行 ResNet50 模型所需的運算子。它要求使用 ORT 格式模型(因為它使用 --minimal_build=extended 構建)。它支援 NNAPI 和 XNNPACK 執行提供程式。